class: center, middle, inverse, title-slide # Getting Started with R ## Basics of R <br><br> .small[EDUC/PSY 6600] ### Spring 2021 --- # Download Software <img src="figures/R_studio_LaTeX_header.png" width="2133" /> Directions: [Encyclopedia, Vol. 0: Install Software](https://cehs-research.github.io/eBook_install/install-software.html) --- # `R` vs. `R Studio` <br> .huge[If `R` is like a car's engine, then `RStudio` is the steering wheel, the pedals, and the comfortable seat] -- .pull-left[.huge[.center[ `R` [www.r-project.org](https://cran.cnr.berkeley.edu/) ]]] .pull-right[.huge[.center[ `RStudio` [www.rstudio.com](https://www.rstudio.com/products/rstudio/download/) ]]] --- # Focus on what is needed in `R` <br> .center[.Huge[ ".dcoral[Success] is neither magical nor mysterious. Success is the natural consequence of consistently applying the .nicegreen[basic fundamentals]." --- Jim Rohn ]] .footnote[https://www.brainyquote.com/quotes/jim_rohn_122132?src=t_fundamentals] --- # Intro to `R` .pull-left[.huge[ Why Use `R`? ] .large[ - .coral[**Free**]ly available - Almost always up-to-date - Best .bluer[data visualizations] - .nicegreen[Syntax oriented] (easy to reproduce analyses) - Gets updated regularly - You can make your .gray1[own functionality] (e.g., `table1()`) ]] -- .pull-right[ .huge[`table1()` produces 👇] <br> 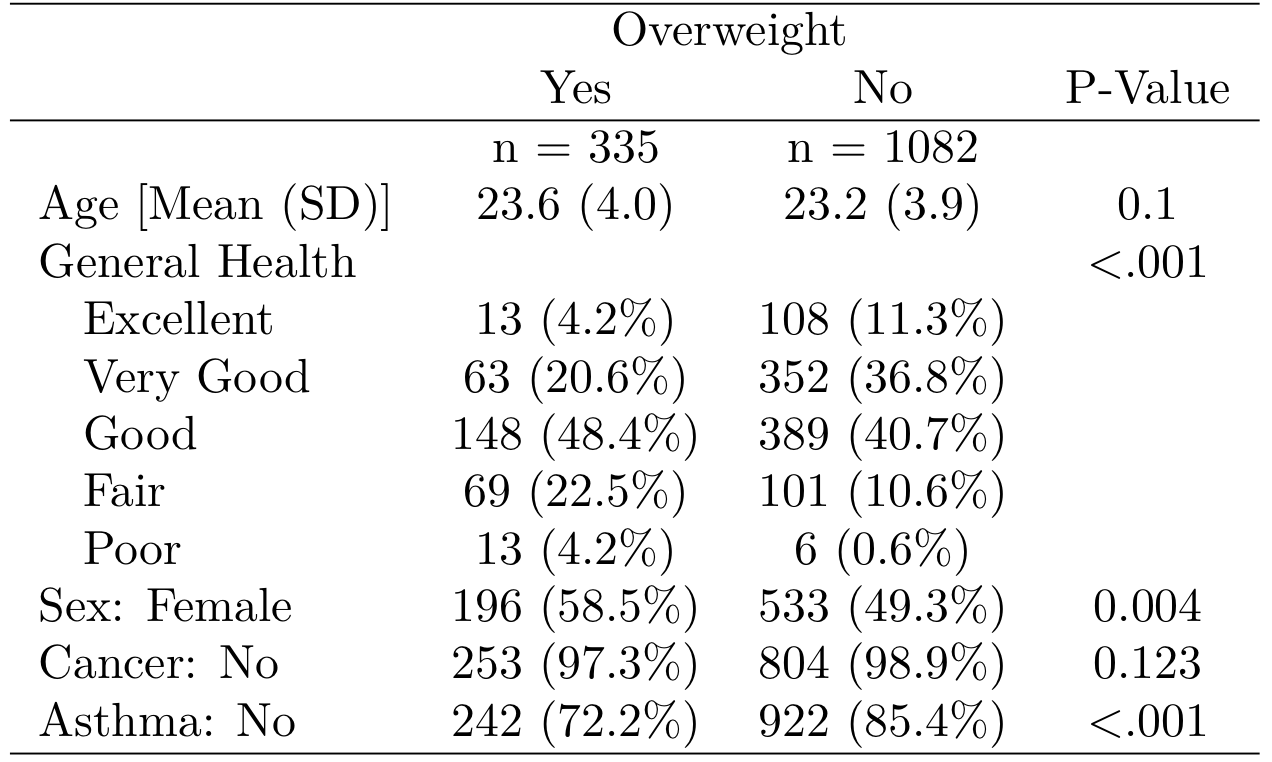 ] --- count: false # Intro to `R` .pull-left[.huge[ Why Use `R`? ] .large[ - .coral[**Free**]ly available - Almost always up-to-date - Best .bluer[data visualizations] - .nicegreen[Syntax oriented] (easy to reproduce analyses) - Gets updated regularly - You can make your .gray1[own functionality] (e.g., `table1()`) ]] .pull-right[.huge[ Any Issues? ] .large[ - Learning curve - Too extensive (people often focus on too much) - Advisor's sometimes don't use it The pro's heavily outweight the con's *if* you are willing to use it. It can save you tons of time in the long-run. ]] --- ## .coral[Objects] are Nouns Virtual objects are like physical objects (e.g., a car is good to travel in, a table not so much) `R` uses virtual objects - a `vector` is values concatinated together - a `data.frame` is a group of vectors of the same length -- .pull-left[ .large[.bluer[Vector]] concatinate or combine ```r c(1, 3, 5, 7, 11, 13) ``` ``` > [1] 1 3 5 7 11 13 ``` ] -- .pull-right[ .large[.bluer[Data Frame]] named vectors of the same length ```r data.frame(x = c(1, 3, 5, 7), y = c(2, 4, 6, 8)) ``` ``` > x y > 1 1 2 > 2 3 4 > 3 5 6 > 4 7 8 ``` ] --- ## .coral[Objects]: save into global environment .pull-left[ .large[Assignment symbol: .coral[<-]] .large[.bluer[Constant]] ```r fred <- 13 ``` ```r fred ``` ``` > [1] 13 ``` .large[.bluer[Vector]] ```r odds <- c(1, 3, 5, 7, 11, 13) ``` ```r odds ``` ``` > [1] 1 3 5 7 11 13 ``` ] -- .pull-right[ .large[.bluer[Data Frame]] ```r df <- data.frame(x = c(1, 3, 5, 7), y = c(2, 4, 6, 8)) ``` ```r df ``` ``` > x y > 1 1 2 > 2 3 4 > 3 5 6 > 4 7 8 ``` ] --- ## .coral[Class] of a variable: .nicegreen[numeric (dbl)] .pull-leftbig[ ```r df <- data.frame(id = c(100, 101, 102, 103), name = c("Joe", "Jill", "Meg", "Pat"), age = c(10, 9, 10, 11), trt = as.factor(c("A", "B", "A", "B"))) ``` ```r df ``` ``` > id name age trt > 1 100 Joe 10 A > 2 101 Jill 9 B > 3 102 Meg 10 A > 4 103 Pat 11 B ``` ] -- .pull-rightsmall[ .large[dataframe.coral[$]variable] ```r df$id ``` ``` > [1] 100 101 102 103 ``` .large[numbers are not quoted] ```r class(df$id) ``` ``` > [1] "numeric" ``` ] --- ## .coral[Class] of a variable: .nicegreen[numeric (dbl)] .pull-leftbig[ ```r df <- data.frame(id = c(100, 101, 102, 103), name = c("Joe", "Jill", "Meg", "Pat"), age = c(10, 9, 10, 11), trt = as.factor(c("A", "B", "A", "B"))) ``` ```r df ``` ``` > id name age trt > 1 100 Joe 10 A > 2 101 Jill 9 B > 3 102 Meg 10 A > 4 103 Pat 11 B ``` ] .pull-rightsmall[ .large[dataframe.coral[$]variable] ```r df$age ``` ``` > [1] 10 9 10 11 ``` .large[numbers are not quoted] ```r class(df$age) ``` ``` > [1] "numeric" ``` ] --- ## .coral[Class] of a variable: .nicegreen[character (chr)] .pull-leftbig[ ```r df <- data.frame(id = c(100, 101, 102, 103), name = c("Joe", "Jill", "Meg", "Pat"), age = c(10, 9, 10, 11), trt = as.factor(c("A", "B", "A", "B"))) ``` ```r df ``` ``` > id name age trt > 1 100 Joe 10 A > 2 101 Jill 9 B > 3 102 Meg 10 A > 4 103 Pat 11 B ``` ] .pull-rightsmall[ .large[dataframe.coral[$]variable] ```r df$name ``` ``` > [1] "Joe" "Jill" "Meg" "Pat" ``` .large[text is quoted] ```r class(df$name) ``` ``` > [1] "character" ``` ] --- ## .coral[Class] of a variable: .nicegreen[factor (fct)] .pull-leftbig[ ```r df <- data.frame(id = c(100, 101, 102, 103), name = c("Joe", "Jill", "Meg", "Pat"), age = c(10, 9, 10, 11), trt = as.factor(c("A", "B", "A", "B"))) ``` ```r df ``` ``` > id name age trt > 1 100 Joe 10 A > 2 101 Jill 9 B > 3 102 Meg 10 A > 4 103 Pat 11 B ``` ] .pull-rightsmall[ .large[dataframe.coral[$]variable] ```r df$trt ``` ``` > [1] A B A B > Levels: A B ``` .large[factors have levels] ```r class(df$trt) ``` ``` > [1] "factor" ``` ] --- ## .coral[Functions] are Verbs .pull-left[.large[ Generally looks like: `stuff(arg1, arg2)` ...or... `pkg::stuff(arg1, arg2)` - `pkg` package the function is from - `stuff` function's name - `()` surround the arguments - `arg1` and `arg2` arguments or options ]] -- .pull-right[ .large[Example: "mean" function - `mean()` - 1 argument required: a variable - returns variable's average ] ```r ## This is a comment mean(df$age) ``` ``` > [1] 10 ``` ...does the same thing... ```r base::mean(df$age) ``` ``` > [1] 10 ``` ] --- ## .coral[Functions] are Verbs <img src="figures/data_verb_input_output.png" width="1656" /> --- ## .coral[Missing Values] are lack of data - `NA` represents missing or blank values - there are no quotes around the `NA` .pull-leftbig[ ```r df <- data.frame(id = c(100, 101, 102, 103), name = c("Joe", "Jill", "Meg", "Pat"), age = c(10, 9.5, NA, 11), trt = as.factor(c("A", "B", "A", "B"))) ``` ```r df ``` ``` > id name age trt > 1 100 Joe 10.0 A > 2 101 Jill 9.5 B > 3 102 Meg NA A > 4 103 Pat 11.0 B ``` ] -- .pull-rightsmall[ ```r mean(df$age) ``` ``` > [1] NA ``` default: - keeps in missing values - NA in data cases NA in mean ```r mean(df$age, na.rm = TRUE) ``` ``` > [1] 10.16667 ``` ] --- ## .coral[Functions]: what package is it from? .pull-leftsmall[ Function in Base R ```r dim(df) ``` ``` > [1] 4 4 ``` ```r names(df) ``` ``` > [1] "id" "name" "age" "trt" ``` ] -- .pull-rightbig[ Function from a specific package ```r tibble::glimpse(df) ``` ``` > Rows: 4 > Columns: 4 > $ id <dbl> 100, 101, 102, 103 > $ name <chr> "Joe", "Jill", "Meg", "Pat" > $ age <dbl> 10.0, 9.5, NA, 11.0 > $ trt <fct> A, B, A, B ``` ] --- ## The .coral[Tidyverse] <img src="figures/tidyverse.png" width="2205" /> --- ## The .coral[Tidyverse] https://rworkshop.uni.lu/lectures/lecture05_dplyr.html#1 ```r library(tidyverse) ``` --- ## The .coral[Pipe] links steps The symbol is typed .nicegreen[`%>%`] .pull-left[ ```r mean(df$age, na.rm = TRUE) ``` ``` > [1] 10.16667 ``` ```r df$age %>% mean(na.rm = TRUE) ``` ``` > [1] 10.16667 ``` ] .pull-right[ <img src="figures/pipe_verb.PNG" width="1745" /> ] --- <img src="figures/pipeline_1.PNG" width="1863" /> --- <img src="figures/pipeline_step1.PNG" width="75%" /> -- <img src="figures/pipeline_step2.PNG" width="75%" /> --- ## Build a .coral[Pipeline] <img src="figures/chaining_data_verbs.png" width="2317" /> --- <img src="figures/pipeline_1.PNG" width="1863" /> --- <img src="figures/pipline_compare.PNG" width="75%" /> --- <img src="figures/pipline_compare_arrows.PNG" width="75%" /> --- <img src="figures/pipeline_stesp_pipe.PNG" width="75%" /> --- ## Build a .coral[Pipeline] <img src="figures/assembly-line.png" width="1923" /> --- # Important first steps in `R` .large[.large[ 1. Read in Data 2. Quickly assess the data 3. Clean the data 4. Analyze the data ]] -- .large[We'll show each of these over the next few weeks starting with reading in, assessing and cleaning the data] --- # Read in the data .huge[Data comes in various files:] .pull-left[.large[ - CSV - tab-delimited - SPSS - Excel ]] .pull-right[.large[ - SAS - Stata - Mplus - etc. ]] -- ### `R` can read all types -- .huge[Generally, it all works in a similar way] --- # Read in data: FORMAT .large[Text: .bluer[Comma-seperated]] ```r my_data <- read.csv("my_data_file.csv") ``` -- .large[Text: .bluer[tab-delimited]] ```r my_data <- read.delim("my_data_file.txt") ``` -- .large[.bluer[Excel]]: .xls, .xlsx ```r library(readxl) my_data <- readxl::read_excel("my_data_file.xlsx") ``` -- .large[.bluer[SPSS]]: .sav ```r library(haven) my_data <- haven::read_spss("my_data_file.sav") ``` --- background-image: url(figures/fig_inho_data_desc.png) background-position: 50% 90% background-size: 800px # Let's use the data from the book --- # Steps for .dcoral[Preparing] the Data for Analysis .large[.large[ 1. .coral[Get the data] 2. .nicegreen[Prep the data] - Variable Labels - Value Labels - Missing Values 3. .bluer[Compute] new variables and values (fill in missing codes, recode scores, categorize/group values, combine) 4. Get .dcoral[descriptives] using `tableF()` and `table1()` from the `furniture` package to check what is going on ]] --- # Step 1: Get the data Data is in .xls form (Excel) saved in the folder with .Rmd file ```r library(readxl) d <- readxl::read_excel("Ihno_dataset.xls") d ``` ``` > # A tibble: 100 x 18 > Sub_num Gender Major Reason Exp_cond Coffee Num_cups Phobia Prevmath Mathquiz > <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> > 1 1 1 1 3 1 1 0 1 3 43 > 2 2 1 1 2 1 0 0 1 4 49 > 3 3 1 1 1 1 0 0 4 1 26 > 4 4 1 1 1 1 0 0 4 0 29 > 5 5 1 1 1 1 0 1 10 1 31 > 6 6 1 1 1 2 1 1 4 1 20 > 7 7 1 1 1 2 0 0 4 2 13 > 8 8 1 1 3 2 1 2 4 1 23 > 9 9 1 1 1 2 0 0 4 1 38 > 10 10 1 1 1 2 1 2 5 0 NA > # ... with 90 more rows, and 8 more variables: Statquiz <dbl>, Exp_sqz <dbl>, > # Hr_base <dbl>, Hr_pre <dbl>, Hr_post <dbl>, Anx_base <dbl>, Anx_pre <dbl>, > # Anx_post <dbl> ``` --- # Step 2: Prep the data ```r library(tidyverse) d_clean <- d %>% dplyr::mutate(MajorF = factor(Major, levels = c(1, 2, 3, 4, 5), labels = c("Psychology", "Premed", "Biology", "Sociology", "Economics"))) %>% dplyr::mutate(Coffee = factor(Coffee)) d_clean ``` ``` > # A tibble: 100 x 19 > Sub_num Gender Major Reason Exp_cond Coffee Num_cups Phobia Prevmath Mathquiz > <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> > 1 1 1 1 3 1 1 0 1 3 43 > 2 2 1 1 2 1 0 0 1 4 49 > 3 3 1 1 1 1 0 0 4 1 26 > 4 4 1 1 1 1 0 0 4 0 29 > 5 5 1 1 1 1 0 1 10 1 31 > 6 6 1 1 1 2 1 1 4 1 20 > 7 7 1 1 1 2 0 0 4 2 13 > 8 8 1 1 3 2 1 2 4 1 23 > 9 9 1 1 1 2 0 0 4 1 38 > 10 10 1 1 1 2 1 2 5 0 NA > # ... with 90 more rows, and 9 more variables: Statquiz <dbl>, Exp_sqz <dbl>, > # Hr_base <dbl>, Hr_pre <dbl>, Hr_post <dbl>, Anx_base <dbl>, Anx_pre <dbl>, > # Anx_post <dbl>, MajorF <fct> ``` --- # Step 3: Compute new variables/values ```r d_clean <- d_clean %>% dplyr::mutate(newVar = Mathquiz / 2) ``` *Note that I removed the other variables just to show you but in reality all the variables are still there. Also I only want to show the first few rows. ```r d_clean %>% dplyr::select(Mathquiz, newVar) %>% head() ``` ``` > # A tibble: 6 x 2 > Mathquiz newVar > <dbl> <dbl> > 1 43 21.5 > 2 49 24.5 > 3 26 13 > 4 29 14.5 > 5 31 15.5 > 6 20 10 ``` --- # Step 4: Get descriptives .pull-left[ ```r library(furniture) furniture::tableF(d_clean, MajorF) ``` ``` > > ----------------------------------------- > MajorF Freq CumFreq Percent CumPerc > Psychology 29 29 29.00% 29.00% > Premed 25 54 25.00% 54.00% > Biology 21 75 21.00% 75.00% > Sociology 15 90 15.00% 90.00% > Economics 10 100 10.00% 100.00% > ----------------------------------------- ``` ] .pull-right[ ```r furniture::tableF(d_clean, Phobia) ``` ``` > > ------------------------------------- > Phobia Freq CumFreq Percent CumPerc > 0 12 12 12.00% 12.00% > 1 15 27 15.00% 27.00% > 2 12 39 12.00% 39.00% > 3 16 55 16.00% 55.00% > 4 21 76 21.00% 76.00% > 5 11 87 11.00% 87.00% > 6 1 88 1.00% 88.00% > 7 4 92 4.00% 92.00% > 8 4 96 4.00% 96.00% > 9 1 97 1.00% 97.00% > 10 3 100 3.00% 100.00% > ------------------------------------- ``` ] --- # Step 4: Get descriptives ```r d_clean %>% dplyr::group_by(MajorF) %>% furniture::table1(Mathquiz, Phobia, Coffee) ``` ``` > Using dplyr::group_by() groups: MajorF ``` ``` > > ------------------------------------------------------------------- > MajorF > Psychology Premed Biology Sociology Economics > n = 25 n = 21 n = 19 n = 12 n = 8 > Mathquiz > 29.6 (8.9) 31.0 (8.2) 24.2 (10.4) 28.0 (10.4) 35.4 (6.3) > Phobia > 3.6 (2.4) 3.0 (2.5) 3.7 (2.6) 3.2 (3.0) 1.8 (1.4) > Coffee > 0 17 (68%) 11 (52.4%) 10 (52.6%) 8 (66.7%) 4 (50%) > 1 8 (32%) 10 (47.6%) 9 (47.4%) 4 (33.3%) 4 (50%) > ------------------------------------------------------------------- ``` --- class: inverse, center, middle # Questions? --- class: inverse, center, middle # Next Topics ### More Data Manipulation ### Understanding Data via Figures