12 MLM, Longitudinal: Hedeker & Gibbons - Depression
library(tidyverse) # all things tidy
library(pander) # nice looking general tabulations
library(furniture) # nice table1() descriptions
library(texreg) # Convert Regression Output to LaTeX or HTML Tables
library(psych) # contains some useful functions, like headTail()
library(sjstats) # ICC calculations
library(effects) # Estimated Marginal Means
library(performance)
library(VIM) # Visualization and Imputation of Missing Values
library(naniar) # Summaries and Visualizations for Missing Data
library(corrplot) # Visualize correlation matrix
library(lme4) # Linear, generalized linear, & nonlinear mixed models
library(lmerTest)
library(optimx)12.1 Background
Starting in chapter 4, (Hedeker and Gibbons 2006) details analysis of a psychiatric study described by (Reisby et al. 1977). This study focuses on the relationship between Imipramine (IMI) and Desipramine (DMI) plasma levels and clinical response in 66 depressed inpatients (37 endogenous and 29 non-endogenous).
Note: The IMI and DMI measures were only taken in the later weeks, but are not used here.
hamdHamilton Depression Scores (HD)
Independent or predictor variables:
endogDepression Diagnosisendogenous
non-endogenous/reactive
IMI (imipramine) drug-plasma levels (µg/l)
antidepressant given 225 mg/day, weeks 3-6
DMI (desipramine) drug-plasma levels (µg/l)
metabolite of imipramine
data_raw <- read.table("data/riesby.dat.txt") %>%
dplyr::rename(id = "V1",
hamd = "V2",
endog = "V5",
week = "V4") %>%
dplyr::select(-V3, -V6)data_raw %>%
psych::headTail(top = 11, bottom = 8) id hamd week endog
1 101 26 0 0
2 101 22 1 0
3 101 18 2 0
4 101 7 3 0
5 101 4 4 0
6 101 3 5 0
7 103 33 0 0
8 103 24 1 0
9 103 15 2 0
10 103 24 3 0
11 103 15 4 0
... ... <NA> ... ...
389 360 28 4 1
390 360 33 5 1
391 361 30 0 1
392 361 22 1 1
393 361 11 2 1
394 361 8 3 1
395 361 7 4 1
396 361 19 5 112.1.1 Long Format
data_long <- data_raw %>%
dplyr::filter(!is.na(hamd)) %>% # remove NA or missing scores
dplyr::mutate(id = factor(id)) %>% # declare grouping var a factor
dplyr::mutate(endog = factor(endog, # attach labels to a grouping variable
levels = c(0, 1), # order of the levels should match levels
labels = c("Reactive", # order matters!
"Endogenous"))) %>%
dplyr::mutate(hamd = as.numeric(hamd)) %>%
dplyr::select(id, week, endog, hamd) %>% # select the order of variables to include
dplyr::arrange(id, week) # sort observations data_long %>%
psych::headTail(top = 11, bottom = 8) id week endog hamd
1 101 0 Reactive 26
2 101 1 Reactive 22
3 101 2 Reactive 18
4 101 3 Reactive 7
5 101 4 Reactive 4
6 101 5 Reactive 3
7 103 0 Reactive 33
8 103 1 Reactive 24
9 103 2 Reactive 15
10 103 3 Reactive 24
11 103 4 Reactive 15
... <NA> ... <NA> ...
389 609 4 Endogenous 15
390 609 5 Endogenous 2
391 610 0 Endogenous 34
392 610 1 Endogenous <NA>
393 610 2 Endogenous 33
394 610 3 Endogenous 23
395 610 4 Endogenous <NA>
396 610 5 Endogenous 1112.1.2 Wide Format
data_wide <- data_long %>% # save the dataset as a new name
tidyr::pivot_wider(names_from = week,
names_prefix = "hamd_",
values_from = hamd)Notice the missing values, displayed as NA.
data_wide %>%
psych::headTail() id endog hamd_0 hamd_1 hamd_2 hamd_3 hamd_4 hamd_5
1 101 Reactive 26 22 18 7 4 3
2 103 Reactive 33 24 15 24 15 13
3 104 Endogenous 29 22 18 13 19 0
4 105 Reactive 22 12 16 16 13 9
5 <NA> <NA> ... ... ... ... ... ...
6 607 Endogenous 30 39 30 27 20 4
7 608 Reactive 24 19 14 12 3 4
8 609 Endogenous <NA> 25 22 14 15 2
9 610 Endogenous 34 <NA> 33 23 <NA> 1112.2 Exploratory Data Analysis
12.2.1 Diagnosis Group
data_wide %>%
furniture::table1("Depression Type" = endog,
output = "markdown")| Mean/Count (SD/%) | |
|---|---|
| n = 66 | |
| Depression Type | |
| Reactive | 29 (43.9%) |
| Endogenous | 37 (56.1%) |
12.2.2 Missing Data & Attrition
Plot the amount of missing values and the amount of each patter of missing values.
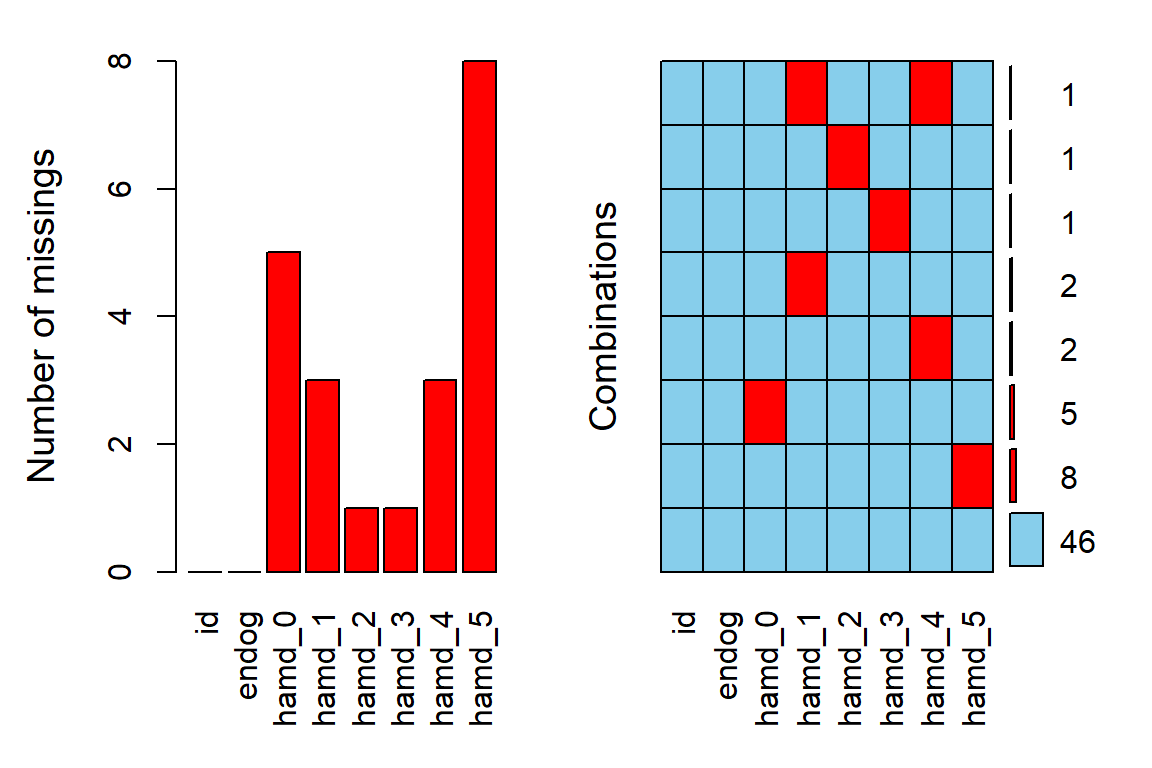
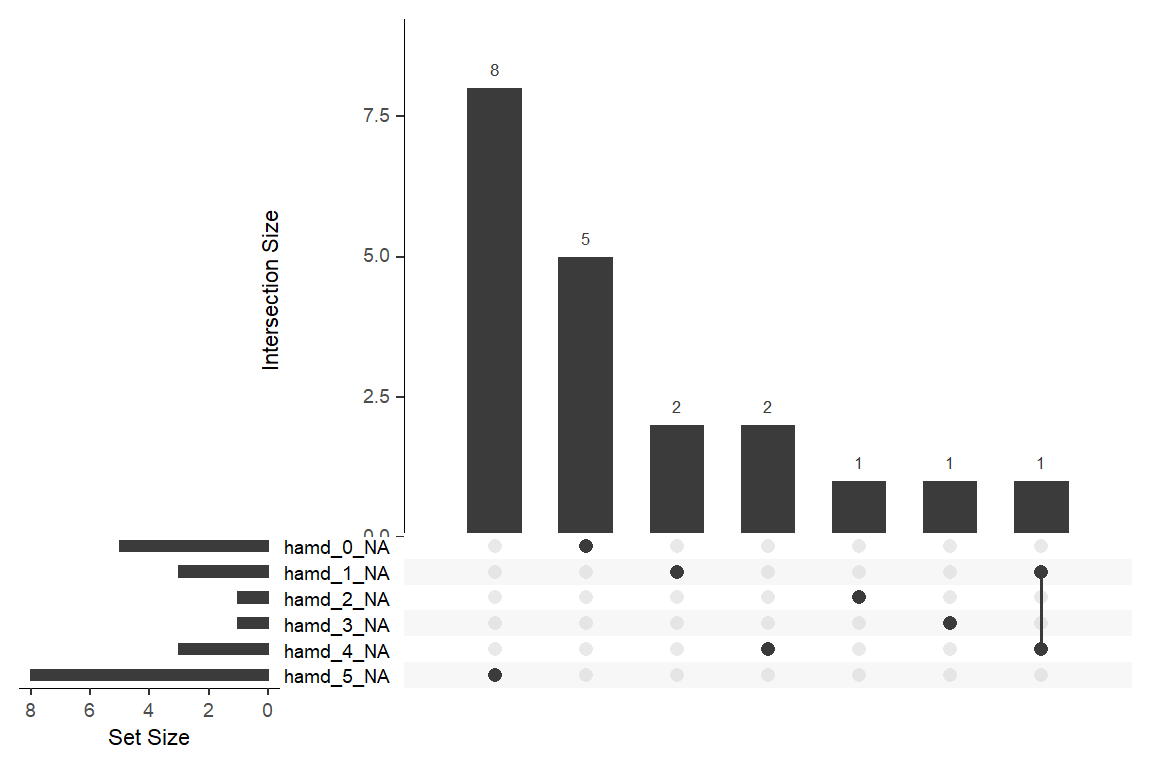
12.2.3 Depression Over Time, by Group
12.2.3.1 Table of Means
Default = COMPLETE CASES ONLY!!!
Note - the sample size at each time point is the same, but subjects are only included if they have data at every time point
data_wide %>%
dplyr::group_by(endog) %>%
furniture::table1("Baseline" = hamd_0,
"Week 1" = hamd_1,
"Week 2" = hamd_2,
"Week 3" = hamd_3,
"Week 4" = hamd_4,
"Week 5" = hamd_5,
total = TRUE,
test = TRUE,
na.rm = TRUE, # default: COMPLETE CASES ONLY!!!!!
digits = 2,
output = "markdown",
caption = "Hamilton Depression Scores Across Time, by Depression Type for Participants with 6 Complete Weeks") | Total | Reactive | Endogenous | P-Value | |
|---|---|---|---|---|
| n = 46 | n = 25 | n = 21 | ||
| Baseline | 0.186 | |||
| 23.15 (4.41) | 22.36 (3.90) | 24.10 (4.87) | ||
| Week 1 | 0.007 | |||
| 21.83 (4.92) | 20.08 (3.68) | 23.90 (5.47) | ||
| Week 2 | 0.292 | |||
| 18.07 (5.17) | 17.32 (4.34) | 18.95 (6.01) | ||
| Week 3 | 0.398 | |||
| 16.61 (6.31) | 15.88 (5.84) | 17.48 (6.86) | ||
| Week 4 | 0.507 | |||
| 13.46 (6.78) | 12.84 (6.68) | 14.19 (6.98) | ||
| Week 5 | 0.468 | |||
| 12.15 (7.57) | 11.40 (6.54) | 13.05 (8.73) |
Specify All data:
note - that the smaple sizes will be different for each time point
data_wide %>%
dplyr::group_by(endog) %>%
furniture::table1("Baseline" = hamd_0,
"Week 1" = hamd_1,
"Week 2" = hamd_2,
"Week 3" = hamd_3,
"Week 4" = hamd_4,
"Week 5" = hamd_5,
total = TRUE,
test = TRUE,
na.rm = FALSE, # default: COMPLETE CASES ONLY!!!!!
digits = 2,
output = "markdown",
caption = "Hamilton Depression Scores Across Time, by Depression Type for All Participants") | Total | Reactive | Endogenous | P-Value | |
|---|---|---|---|---|
| n = 66 | n = 29 | n = 37 | ||
| Baseline | 0.301 | |||
| 23.44 (4.53) | 22.79 (4.12) | 24.00 (4.85) | ||
| Week 1 | 0.033 | |||
| 21.84 (4.70) | 20.48 (3.83) | 23.00 (5.10) | ||
| Week 2 | 0.095 | |||
| 18.31 (5.49) | 17.00 (4.35) | 19.30 (6.08) | ||
| Week 3 | 0.23 | |||
| 16.42 (6.42) | 15.34 (6.17) | 17.28 (6.56) | ||
| Week 4 | 0.298 | |||
| 13.62 (6.97) | 12.62 (6.72) | 14.47 (7.17) | ||
| Week 5 | 0.48 | |||
| 11.95 (7.22) | 11.22 (6.34) | 12.58 (7.96) |
12.2.3.2 Using the LONG formatted dataset
Each person’s data is stored on multiple lines, one for each time point.
FOR ALL DATA!
data_sum_all <- data_long %>%
dplyr::group_by(endog, week) %>% # specify the groups
dplyr::filter(!is.na(hamd)) %>%
dplyr::summarise(hamd_n = n(), # count of valid scores
hamd_mean = mean(hamd), # mean score
hamd_sd = sd(hamd), # standard deviation of scores
hamd_sem = hamd_sd / sqrt(hamd_n)) # stadard error for the mean of scores
data_sum_all %>%
pander::pander()| endog | week | hamd_n | hamd_mean | hamd_sd | hamd_sem |
|---|---|---|---|---|---|
| Reactive | 0 | 28 | 23 | 4.1 | 0.78 |
| Reactive | 1 | 29 | 20 | 3.8 | 0.71 |
| Reactive | 2 | 28 | 17 | 4.3 | 0.82 |
| Reactive | 3 | 29 | 15 | 6.2 | 1.15 |
| Reactive | 4 | 29 | 13 | 6.7 | 1.25 |
| Reactive | 5 | 27 | 11 | 6.3 | 1.22 |
| Endogenous | 0 | 33 | 24 | 4.8 | 0.84 |
| Endogenous | 1 | 34 | 23 | 5.1 | 0.87 |
| Endogenous | 2 | 37 | 19 | 6.1 | 1.00 |
| Endogenous | 3 | 36 | 17 | 6.6 | 1.09 |
| Endogenous | 4 | 34 | 14 | 7.2 | 1.23 |
| Endogenous | 5 | 31 | 13 | 8.0 | 1.43 |
FOR COMPLETE CASES ONLY!!!
data_sum_cc <- data_long %>%
dplyr::group_by(id) %>% # group-by participant
dplyr::filter(!is.na(hamd)) %>%
dplyr::mutate(person_vsae_n = n()) %>% # count the number of valid VSAE scores
dplyr::filter(person_vsae_n == 6) %>% # restrict to only thoes children with 5 valid scores
dplyr::group_by(endog, week) %>% # specify the groups
dplyr::summarise(hamd_n = n(), # count of valid scores
hamd_mean = mean(hamd), # mean score
hamd_sd = sd(hamd), # standard deviation of scores
hamd_sem = hamd_sd / sqrt(hamd_n)) # stadard error for the mean of scores
data_sum_cc %>%
pander::pander()| endog | week | hamd_n | hamd_mean | hamd_sd | hamd_sem |
|---|---|---|---|---|---|
| Reactive | 0 | 25 | 22 | 3.9 | 0.78 |
| Reactive | 1 | 25 | 20 | 3.7 | 0.74 |
| Reactive | 2 | 25 | 17 | 4.3 | 0.87 |
| Reactive | 3 | 25 | 16 | 5.8 | 1.17 |
| Reactive | 4 | 25 | 13 | 6.7 | 1.34 |
| Reactive | 5 | 25 | 11 | 6.5 | 1.31 |
| Endogenous | 0 | 21 | 24 | 4.9 | 1.06 |
| Endogenous | 1 | 21 | 24 | 5.5 | 1.19 |
| Endogenous | 2 | 21 | 19 | 6.0 | 1.31 |
| Endogenous | 3 | 21 | 17 | 6.9 | 1.50 |
| Endogenous | 4 | 21 | 14 | 7.0 | 1.52 |
| Endogenous | 5 | 21 | 13 | 8.7 | 1.90 |
12.2.3.3 Person-Profile Plot or Spaghetti Plot
Use the data in LONG format.
A scatterplot of all observations of depression scores over time, joining the dots of each individual’s data.
NOTE: Not all lines have a point for every week!
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd)) +
geom_point() +
geom_line(aes(group = id)) + # join points that belong to the same "id"
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 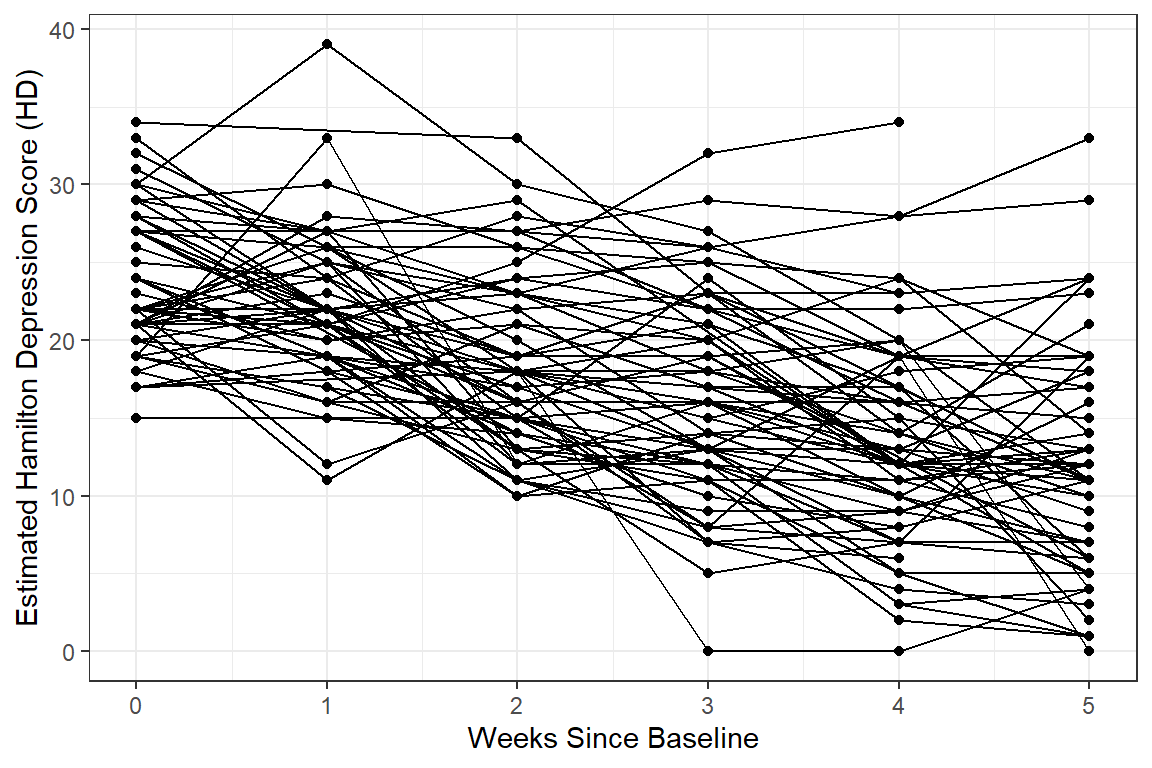
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd,
color = endog)) + # color points and lines by the "endog" variable
geom_line(aes(group = id)) +
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 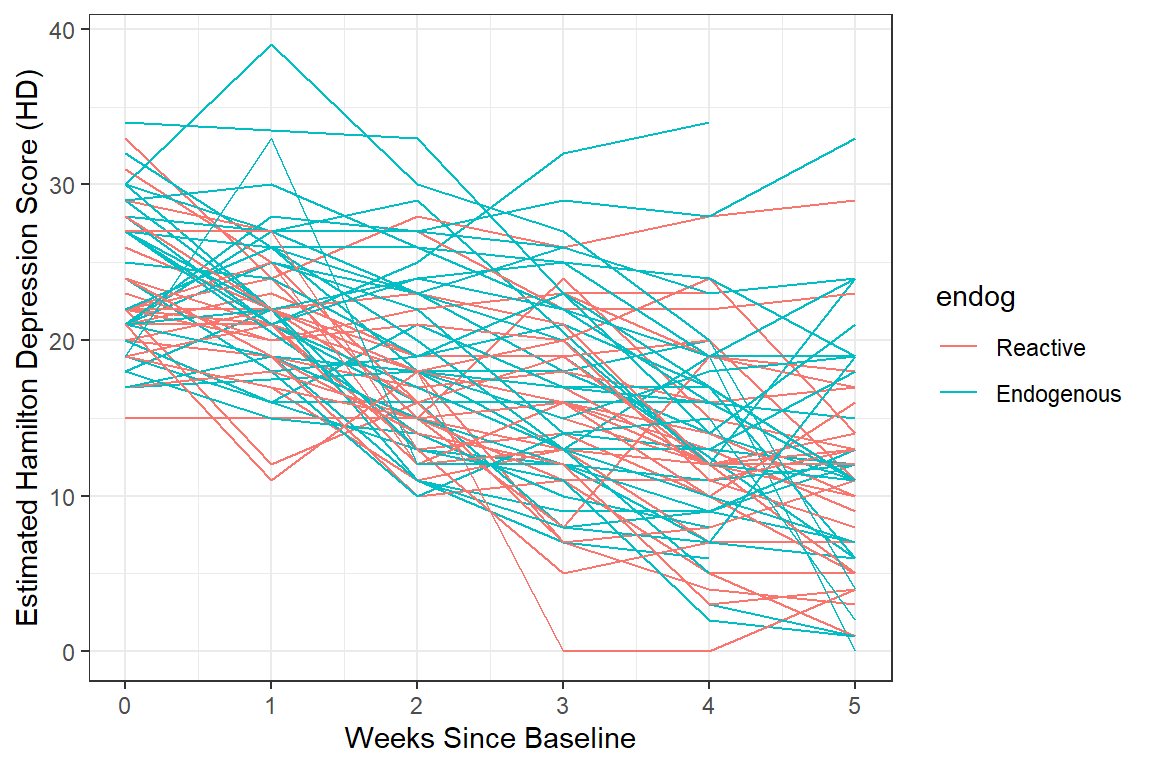
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd)) +
geom_line(aes(group = id)) +
facet_grid( ~ endog) + # side-by-side pandels by the "endog" variable
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 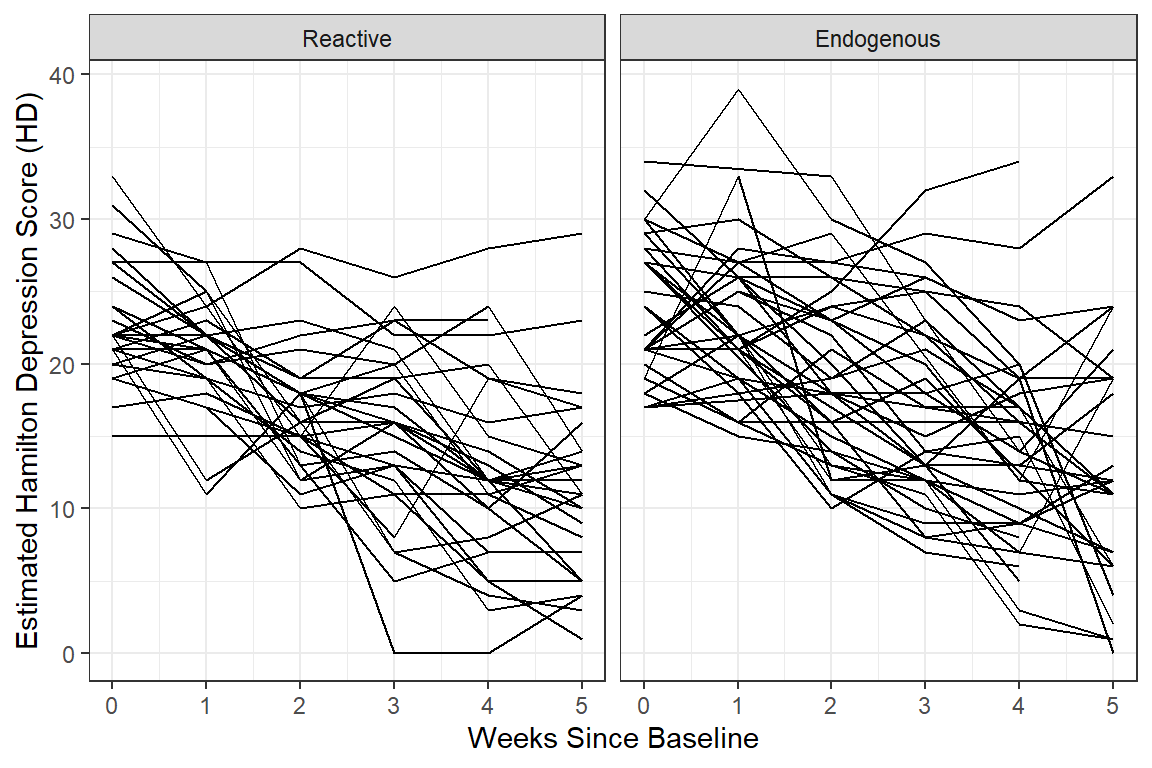
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week %>% factor(),
y = hamd)) +
geom_boxplot() + # compare center and spread
facet_grid( ~ endog) +
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 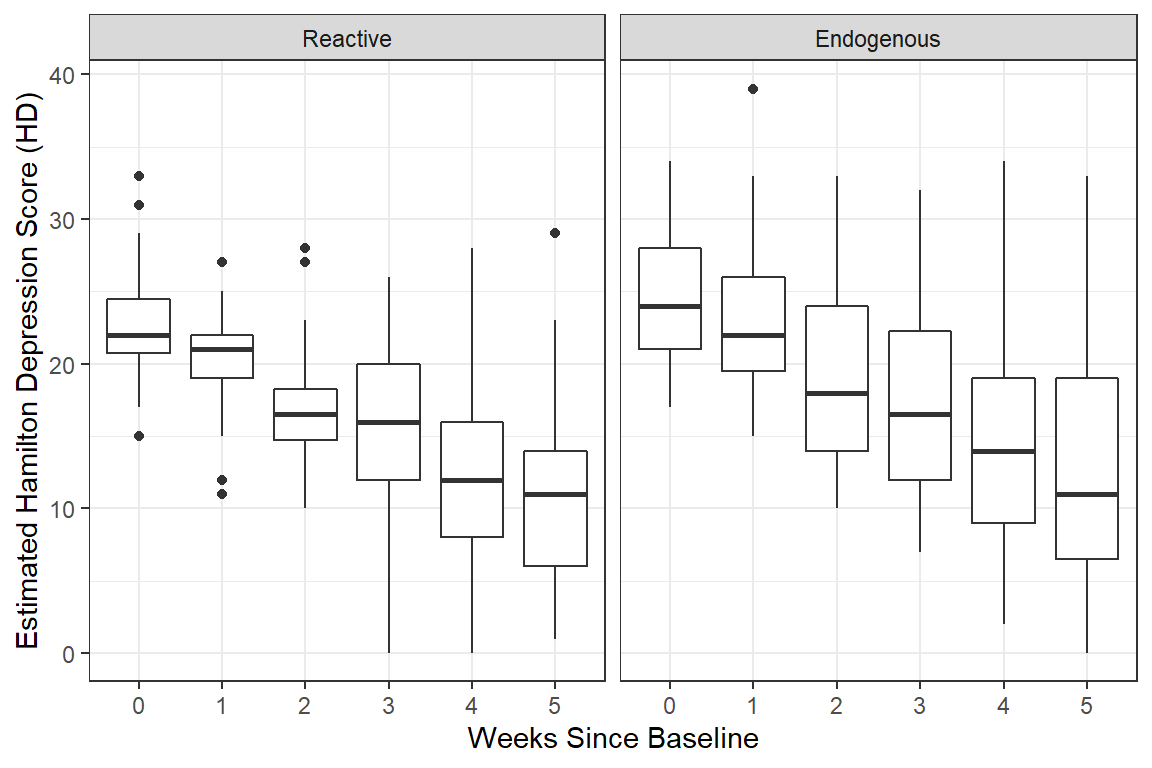
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week %>% factor(),
y = hamd)) +
geom_violin(fill = "gray75") + # similar to boxplots to show distribution
stat_summary() +
stat_summary(aes(group = "endog"),
fun = mean,
geom = "line") +
facet_grid( ~ endog) +
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 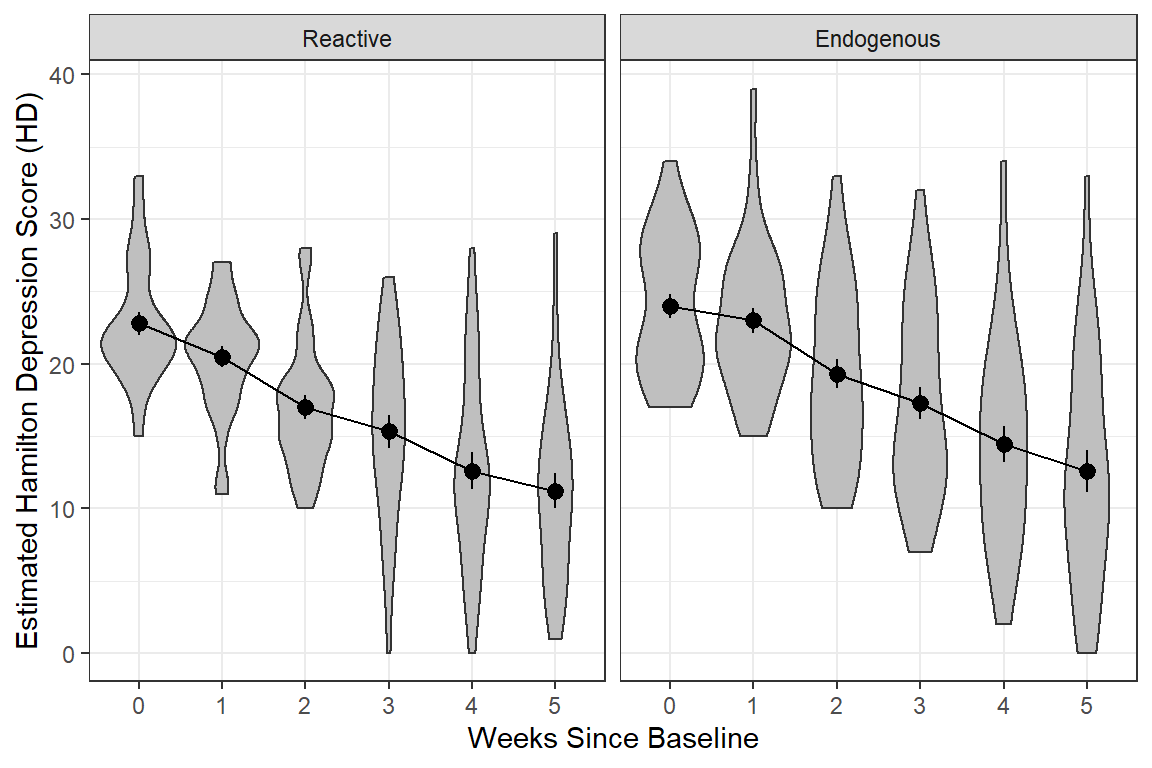
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd,
color = endog)) +
stat_summary() +
stat_summary(aes(group = endog,
linetype = endog),
fun = mean,
geom = "line") +
scale_linetype_manual(values = c("solid", "longdash")) +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm")) +
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 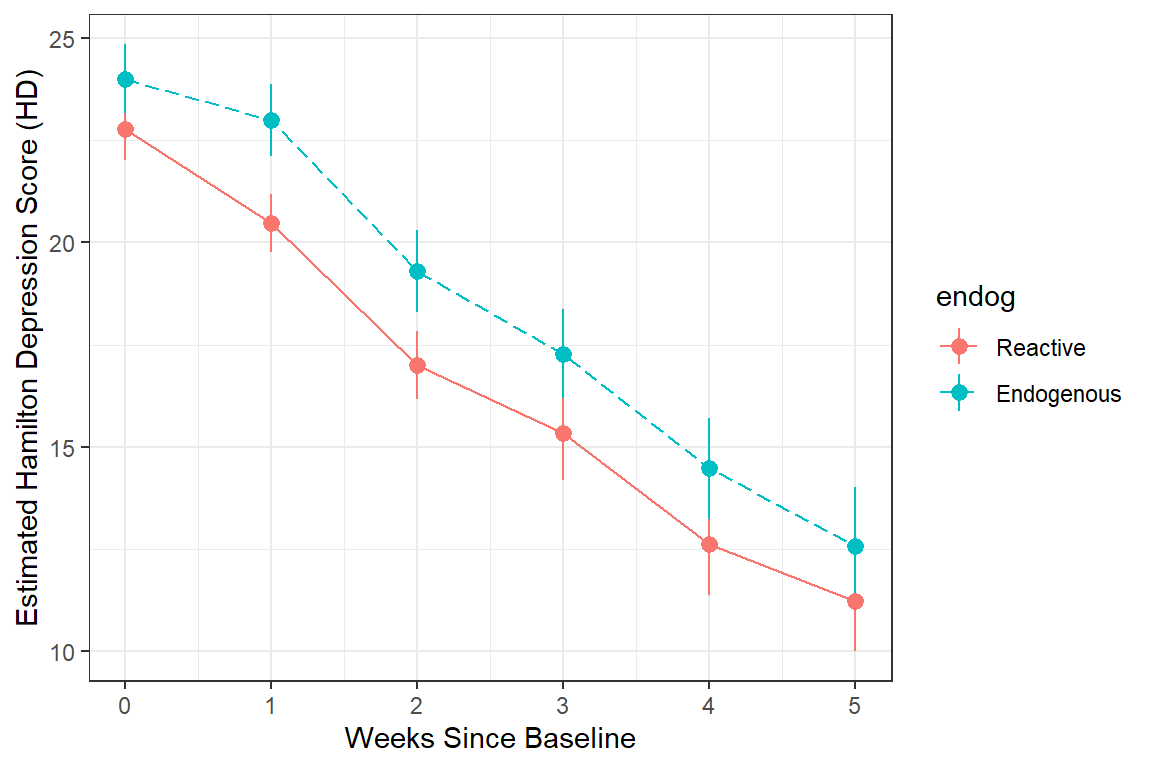
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd)) +
geom_line(aes(group = id)) +
facet_grid( ~ endog) +
geom_smooth() + # DEFAULTS: method = "loess", se = TRUE, color = "blue"
geom_smooth(method = "lm",
se = FALSE,
color = "hot pink")+
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 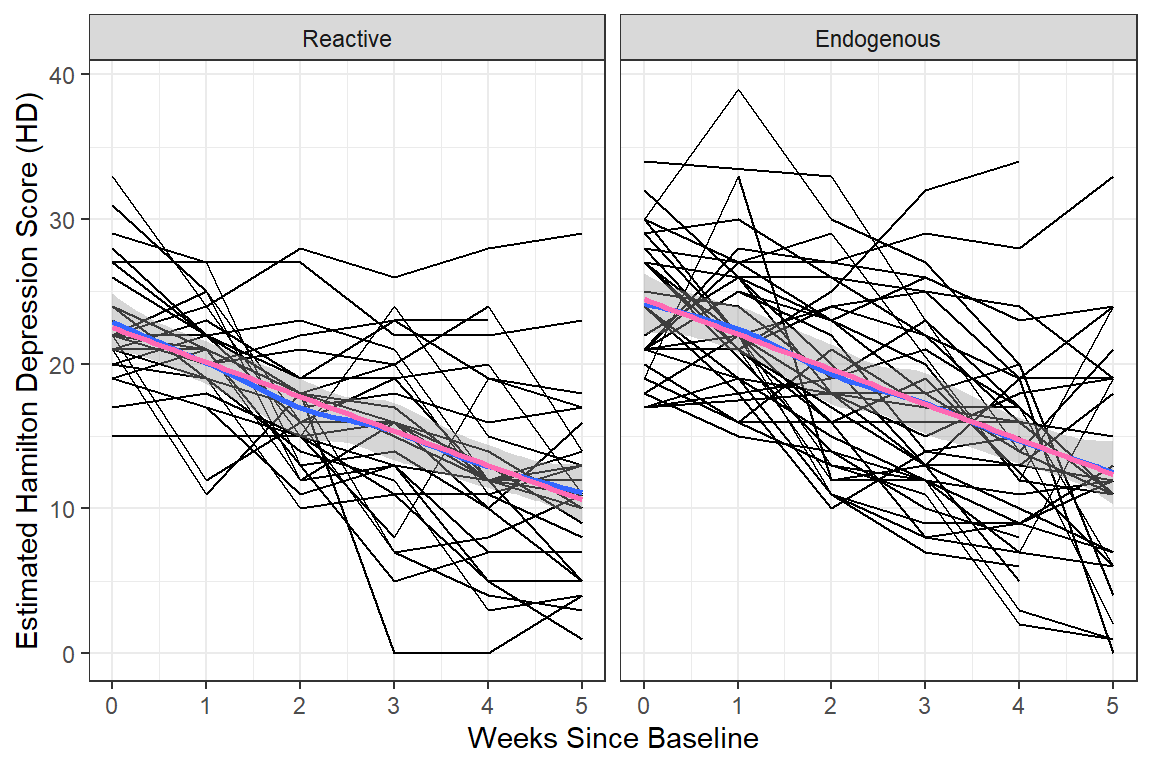
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd)) +
facet_grid( ~ endog) +
geom_smooth(aes(color = "Flexible"),
method = "loess",
se = FALSE,) +
geom_smooth(aes(color = "Linear"),
method = "lm",
se = FALSE) +
scale_color_manual(name = "Smoother Type: ",
values = c("Flexible" = "blue",
"Linear" = "red")) +
theme_bw() +
theme(legend.position = "bottom") +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)") 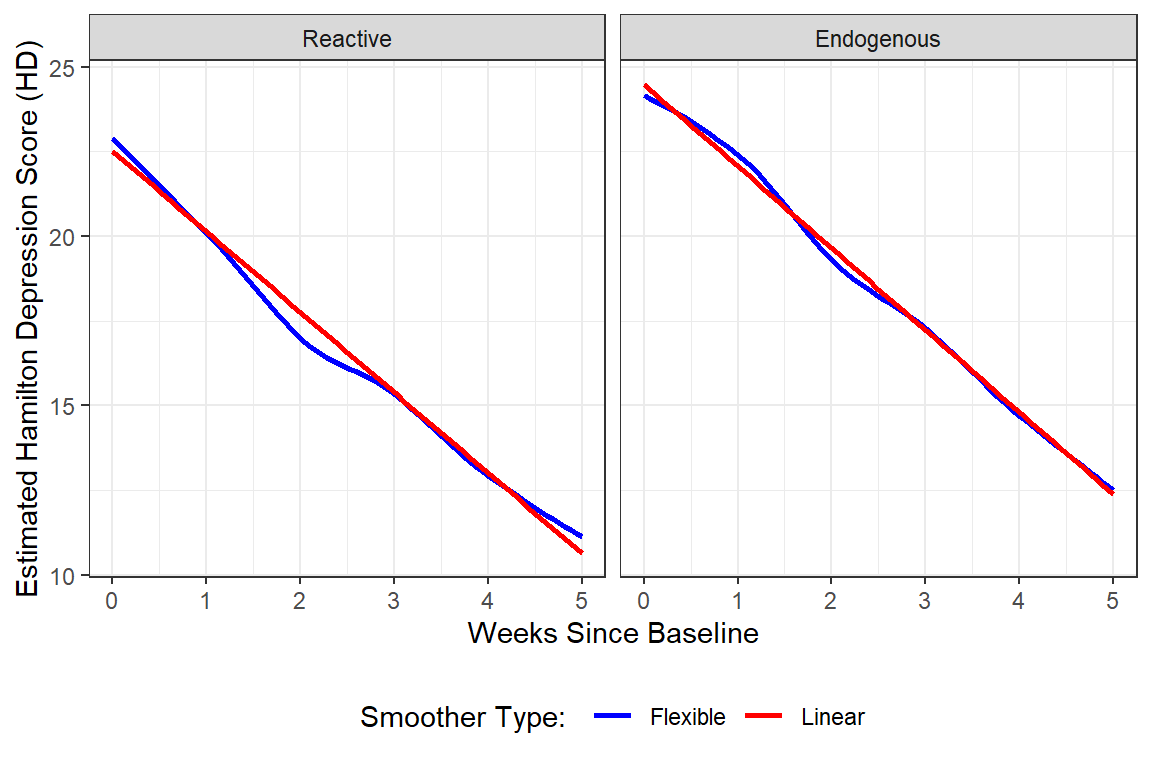
data_long %>%
ggplot(aes(x = week,
y = hamd,
group = endog,
linetype = endog)) +
geom_smooth(method = "loess",
color = "black",
alpha = .25) +
theme_bw() +
scale_linetype_manual(values = c("solid", "longdash")) +
theme(legend.position = c(1, 1),
legend.justification = c(1.1, 1.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Scale",
linetype = "Type of Depression")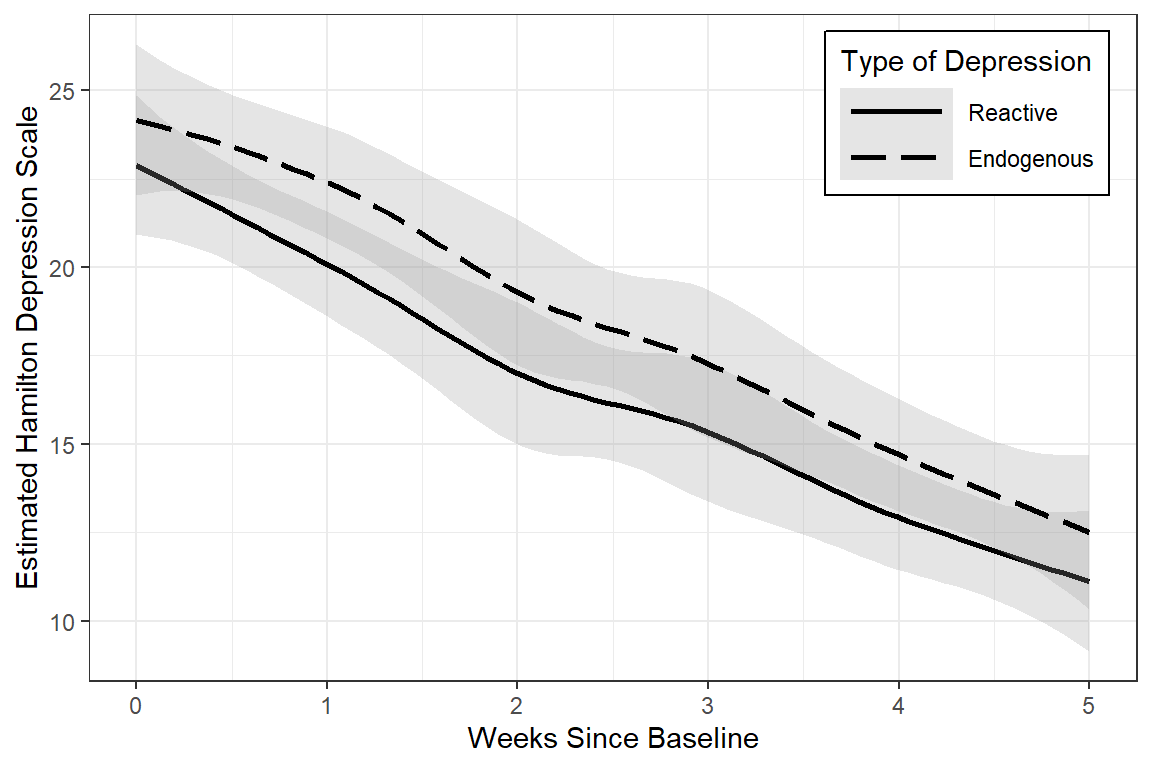
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd,
group = endog,
linetype = endog)) +
geom_smooth(method = "loess",
color = "black",
alpha = .25) +
theme_bw() +
scale_linetype_manual(values = c("solid", "longdash")) +
theme(legend.position = c(1, 1),
legend.justification = c(1.1, 1.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(2, "cm")) +
labs(x = "Weeks Since Baseline",
y = "EsStimated Hamilton Depression Scale",
linetype = "Type of Depression")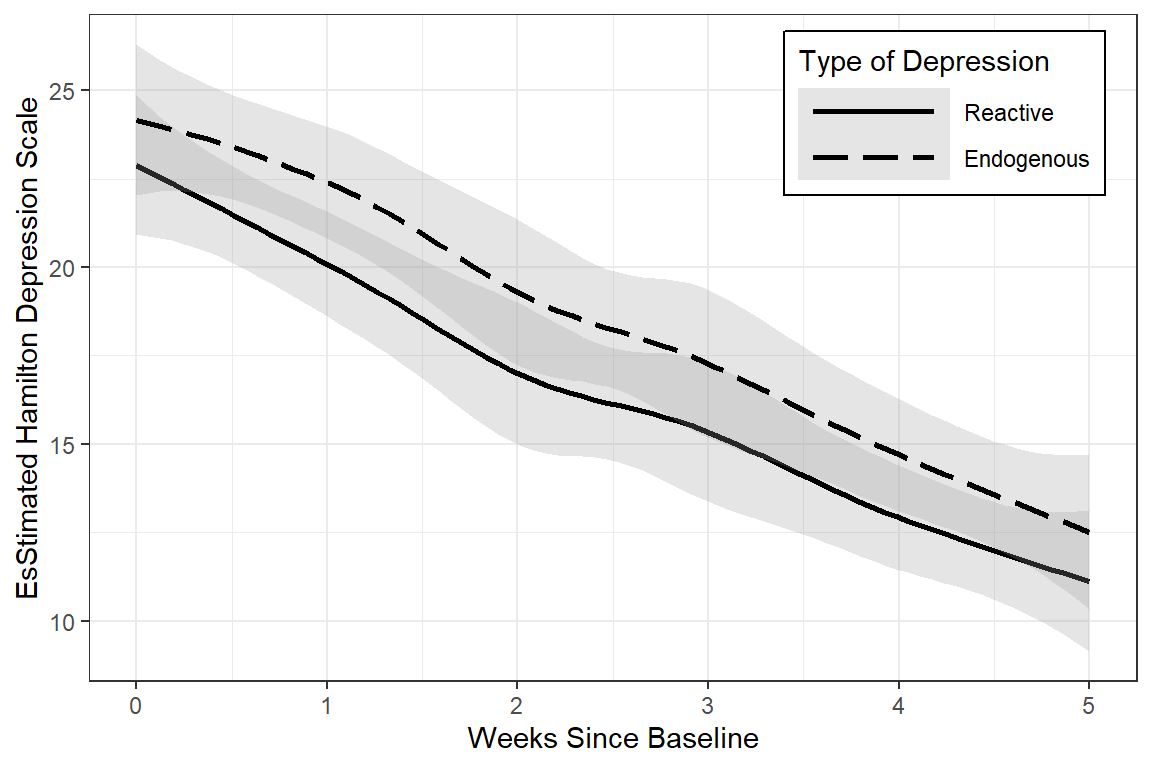
data_long %>%
dplyr::filter(!is.na(hamd)) %>%
ggplot(aes(x = week,
y = hamd,
group = endog,
linetype = endog)) +
geom_smooth(method = "lm",
color = "black",
alpha = .25) +
theme_bw() +
scale_linetype_manual(values = c("solid", "longdash")) +
theme(legend.position = c(1, 1),
legend.justification = c(1.1, 1.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "EStimated Hamilton Depression Scale",
linetype = "Type of Depression")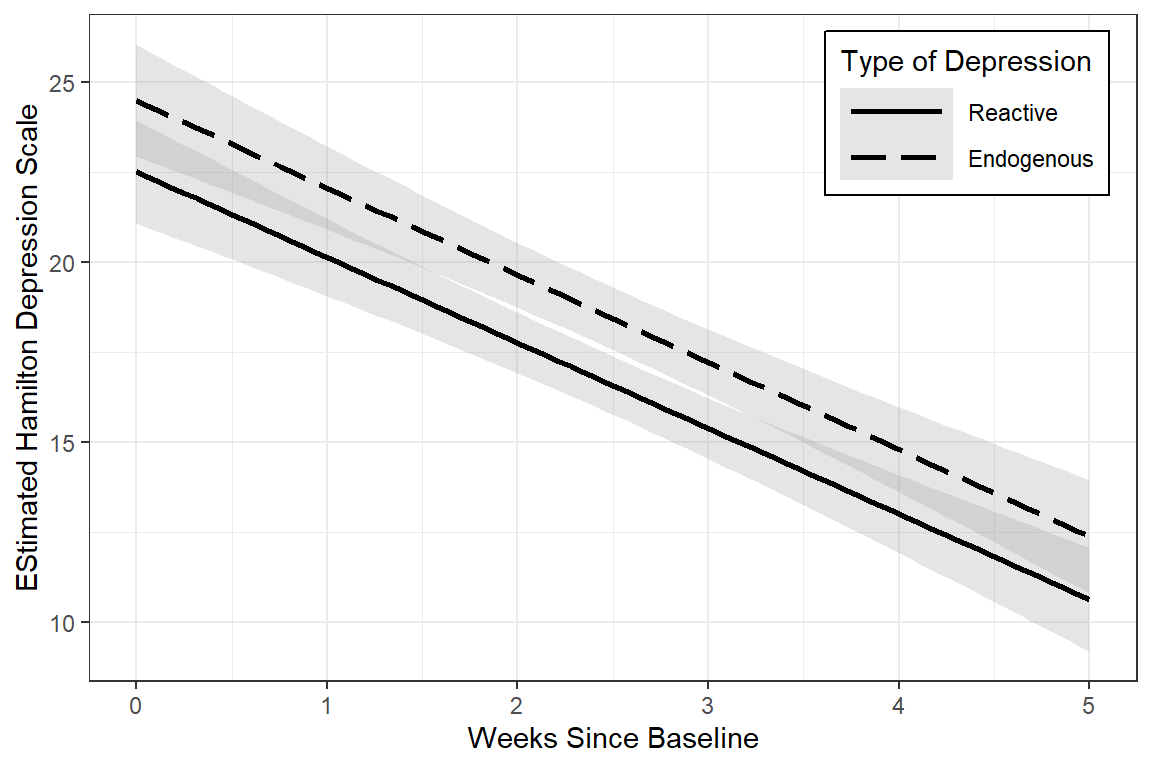
12.3 Patterns in the Outcome Over Time
12.3.1 Variance-Covariance
12.3.1.1 Full Matrix
- Variances are down the diagonal
- Increasing variance over time violates the ANOVA assumption of homogeity of variance
data_wide %>%
dplyr::select(starts_with("hamd_")) %>% # just the outcome(s)
cov(use = "complete.obs") %>% # covariance matrix, LIST-wise deletion
round(3) hamd_0 hamd_1 hamd_2 hamd_3 hamd_4 hamd_5
hamd_0 19.421 10.716 9.523 12.350 9.062 7.376
hamd_1 10.716 24.236 12.545 15.930 11.592 8.471
hamd_2 9.523 12.545 26.773 23.848 23.858 20.657
hamd_3 12.350 15.930 23.848 39.755 33.316 29.728
hamd_4 9.062 11.592 23.858 33.316 45.943 37.107
hamd_5 7.376 8.471 20.657 29.728 37.107 57.332data_wide %>%
dplyr::select(starts_with("hamd_")) %>% # just the outcome(s)
cov(use = "pairwise.complete.obs") %>% # covariance matrix, PAIR-wise deletion
round(3) hamd_0 hamd_1 hamd_2 hamd_3 hamd_4 hamd_5
hamd_0 20.551 10.115 10.139 10.086 7.191 6.278
hamd_1 10.115 22.071 12.277 12.550 10.264 7.720
hamd_2 10.139 12.277 30.091 25.126 24.626 18.384
hamd_3 10.086 12.550 25.126 41.153 37.339 23.992
hamd_4 7.191 10.264 24.626 37.339 48.594 30.513
hamd_5 6.278 7.720 18.384 23.992 30.513 52.12012.3.1.2 Just Variances
Notice the variance in scores increases over time, which is seen in the side-by-side boxplots.
data_wide %>%
dplyr::select(starts_with("hamd_")) %>% # just the outcome(s)
cov(use = "pairwise.complete.obs") %>% # covariance matrix, PAIR-wise deletion
diag() # extracts just the variances hamd_0 hamd_1 hamd_2 hamd_3 hamd_4 hamd_5
20.55082 22.07117 30.09135 41.15288 48.59447 52.12008 12.3.2 Correlation
12.3.2.1 Full Matrix
Pairwise relationships are easier to eye-ball magnitude when presented as correlations, rather than covariances, due to the relative scale.
data_wide %>%
dplyr::select(starts_with("hamd_")) %>% # just the outcome(s)
cor(use = "complete.obs") %>% # correlation matrix - LIST-wise deletion
round(2) hamd_0 hamd_1 hamd_2 hamd_3 hamd_4 hamd_5
hamd_0 1.00 0.49 0.42 0.44 0.30 0.22
hamd_1 0.49 1.00 0.49 0.51 0.35 0.23
hamd_2 0.42 0.49 1.00 0.73 0.68 0.53
hamd_3 0.44 0.51 0.73 1.00 0.78 0.62
hamd_4 0.30 0.35 0.68 0.78 1.00 0.72
hamd_5 0.22 0.23 0.53 0.62 0.72 1.00data_wide %>%
dplyr::select(starts_with("hamd_")) %>% # just the outcome(s)
cor(use = "pairwise.complete.obs") %>% # correlation matrix - PAIR-wise deletion
round(2) hamd_0 hamd_1 hamd_2 hamd_3 hamd_4 hamd_5
hamd_0 1.00 0.49 0.41 0.33 0.23 0.18
hamd_1 0.49 1.00 0.49 0.41 0.31 0.22
hamd_2 0.41 0.49 1.00 0.74 0.67 0.46
hamd_3 0.33 0.41 0.74 1.00 0.82 0.57
hamd_4 0.23 0.31 0.67 0.82 1.00 0.65
hamd_5 0.18 0.22 0.46 0.57 0.65 1.0012.3.2.2 Visualization
Looking for patterns is always easier with a plot. All RM or mixed ANOVA assume sphericity or compound symmetry, meaning that all the correlations in the matrix would be the same. This is not the case for these data. Instead we see a classic pattern of corralary decay. Measures taken close in time, say 1 week apart, exhibit the highest degree of correlation. The farther apart in time that two measures are taken, the less correlated they are. Note that the adjacent measures become more highly correlated, too. This can be due to attrition; later time points having a smaller sample size.
data_wide %>%
dplyr::select(starts_with("hamd_")) %>% # just the outcome(s)
cor(use = "pairwise.complete.obs") %>% # correlation matrix
corrplot::corrplot.mixed(upper = "ellipse")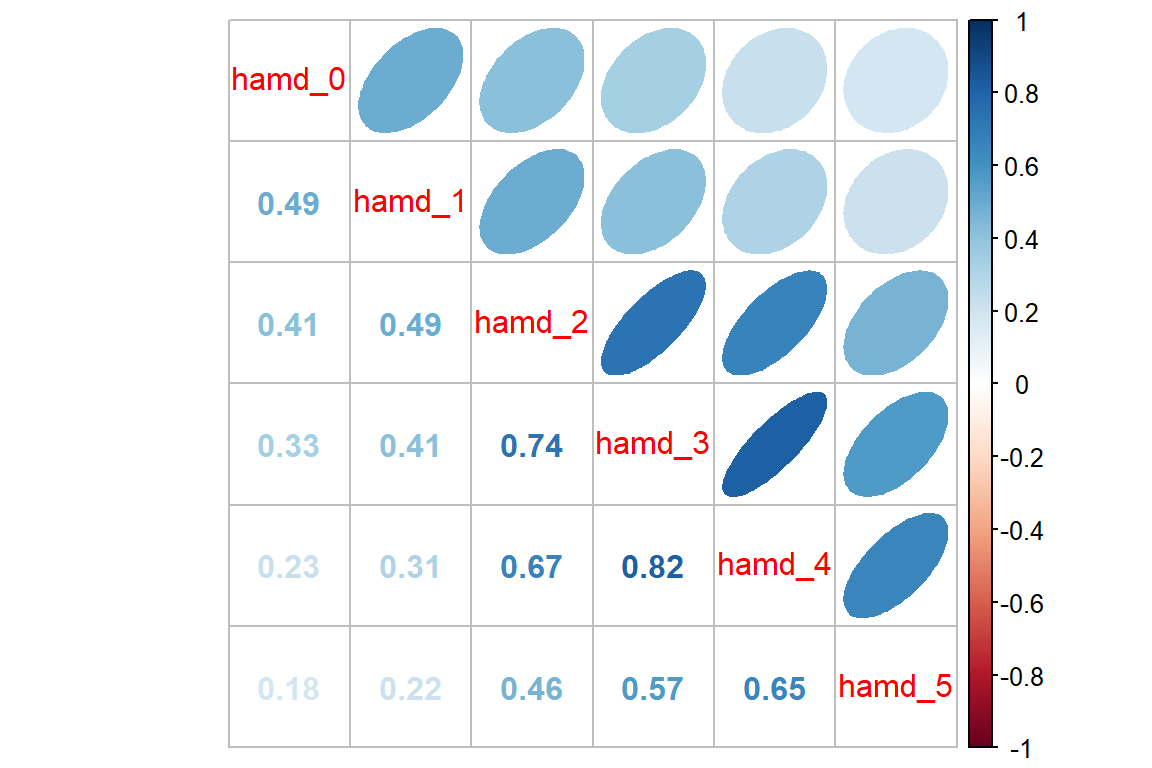
12.3.3 For Each Group
It can be a good ideal to investigate if the groups exhibit a similar pattern in correlation.
Reactive Depression
data_wide %>%
dplyr::filter(endog == "Reactive") %>% # filter observations for the REACTIVE group
dplyr::select(starts_with("hamd_")) %>%
cor(use = "pairwise.complete.obs") %>%
corrplot::corrplot.mixed(upper = "ellipse")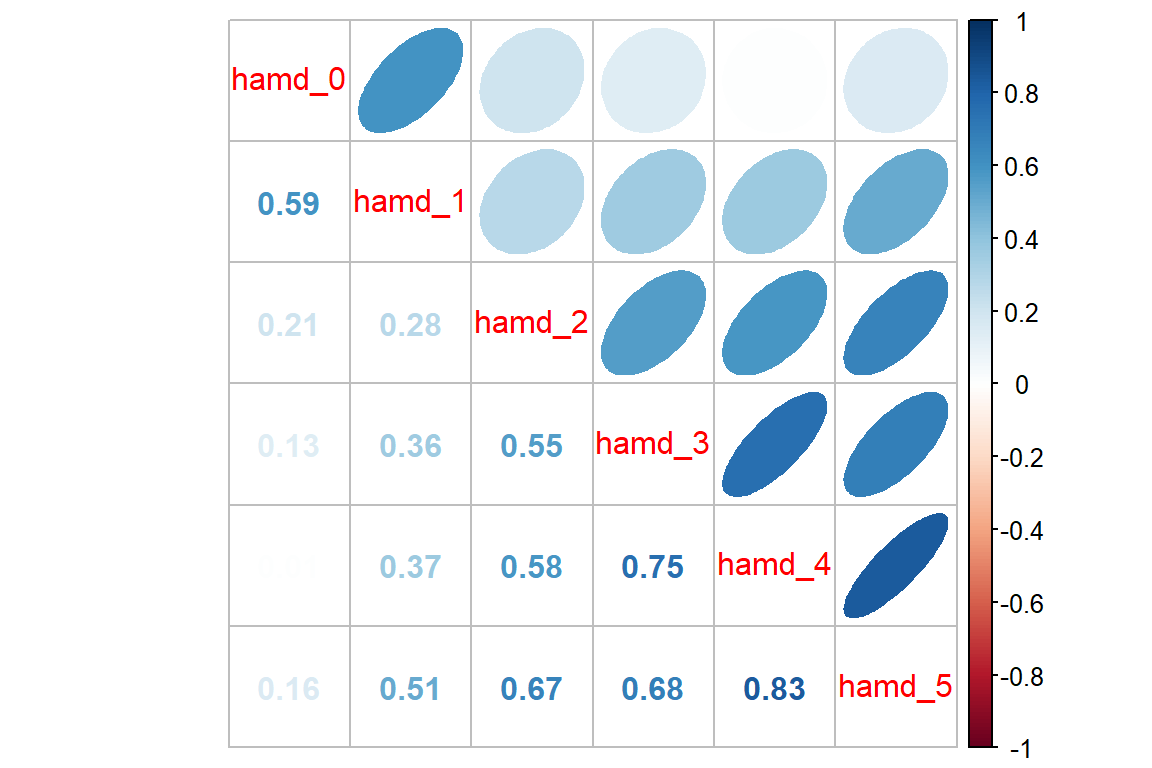
Endogenous Depression
data_wide %>%
dplyr::filter(endog == "Endogenous") %>% # filter observations for the Endogenous group
dplyr::select(starts_with("hamd_")) %>%
cor(use = "pairwise.complete.obs") %>%
corrplot::corrplot.mixed(upper = "ellipse")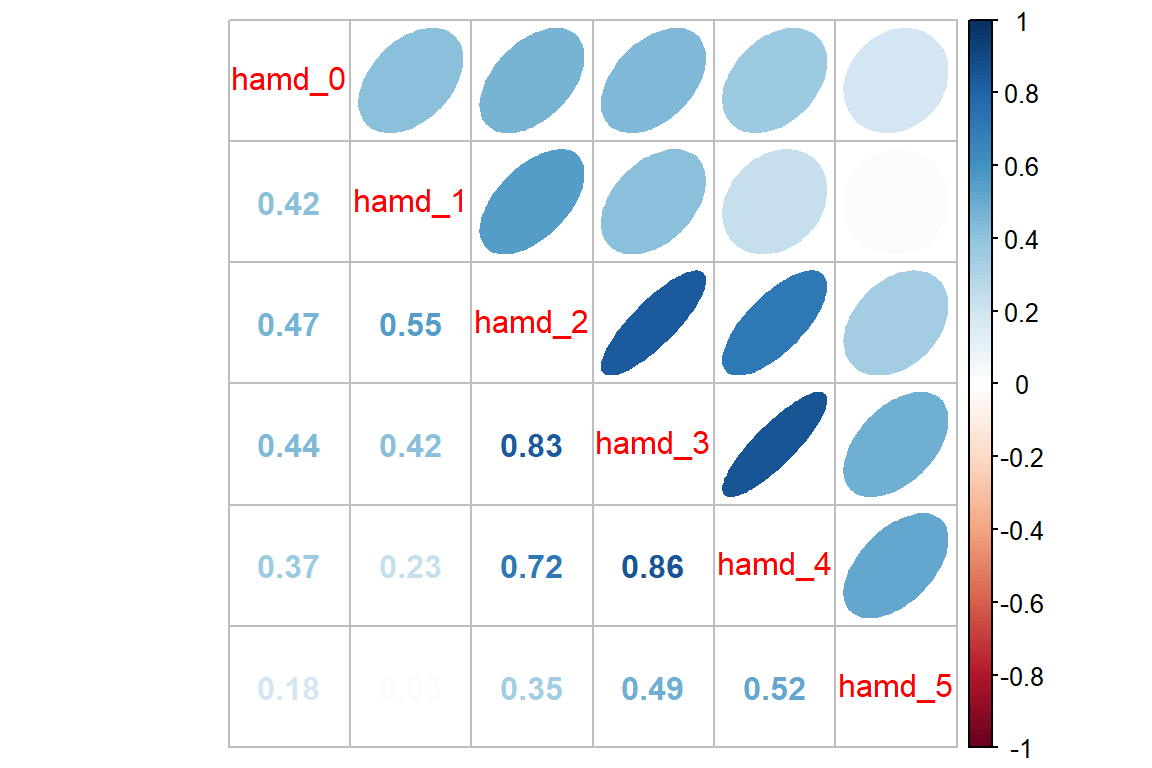
12.4 MLM - Null or Emptly Models
12.4.1 Fit the model
Random Intercepts, with Fixed Intercept and Time Slope (i.e. Trend)….@hedeker2006 section 4.3.5, starting on page 55
Since this situation deals with longitudinal data, it is more appropriate to start off including the time variable in the null model as a fixed effect only.
fit_lmer_week_RI_reml <- lmerTest::lmer(hamd ~ week + (1|id),
data = data_long,
REML = TRUE)12.4.2 Table of Parameter Estimates
texreg::screenreg(fit_lmer_week_RI_reml,
single.row = TRUE,
caption = "MLM: Random Intercepts Null Model fit w/REML",
caption.above = TRUE,
custom.note = "Reproduction of Hedeker's table 4.3 on page 55, except using REML here instead of ML")========================================
Model 1
—————————————-
(Intercept) 23.55 (0.64)
week -2.38 (0.14)
—————————————-
AIC 2294.73
BIC 2310.43
Log Likelihood -1143.36
Num. obs. 375
Num. groups: id 66
Var: id (Intercept) 16.45
Var: Residual 19.10
========================================
Reproduction of Hedeker’s table 4.3 on page 55, except using REML here instead of ML
On average, patients start off with HDRS scores of 23.55 and then change by -2.38 points each week. This weekly improvement of about 2 points a week is statistically significant via the Wald test.
12.4.3 Estimated Marginal Means Plot
Multilevel model on page 55 (Hedeker and Gibbons 2006)
\[ \hat{y} = 23.552 + -2.376 week \]
The fastest way to plot a model is to use the sjPlot::plot_model() function.
Note: you can’t use
interactions::interact_plot()since there is only one predictor (i.e. independent variable) in this model.
sjPlot::plot_model(fit_lmer_week_RI_reml,
type = "pred",
terms = c("week"))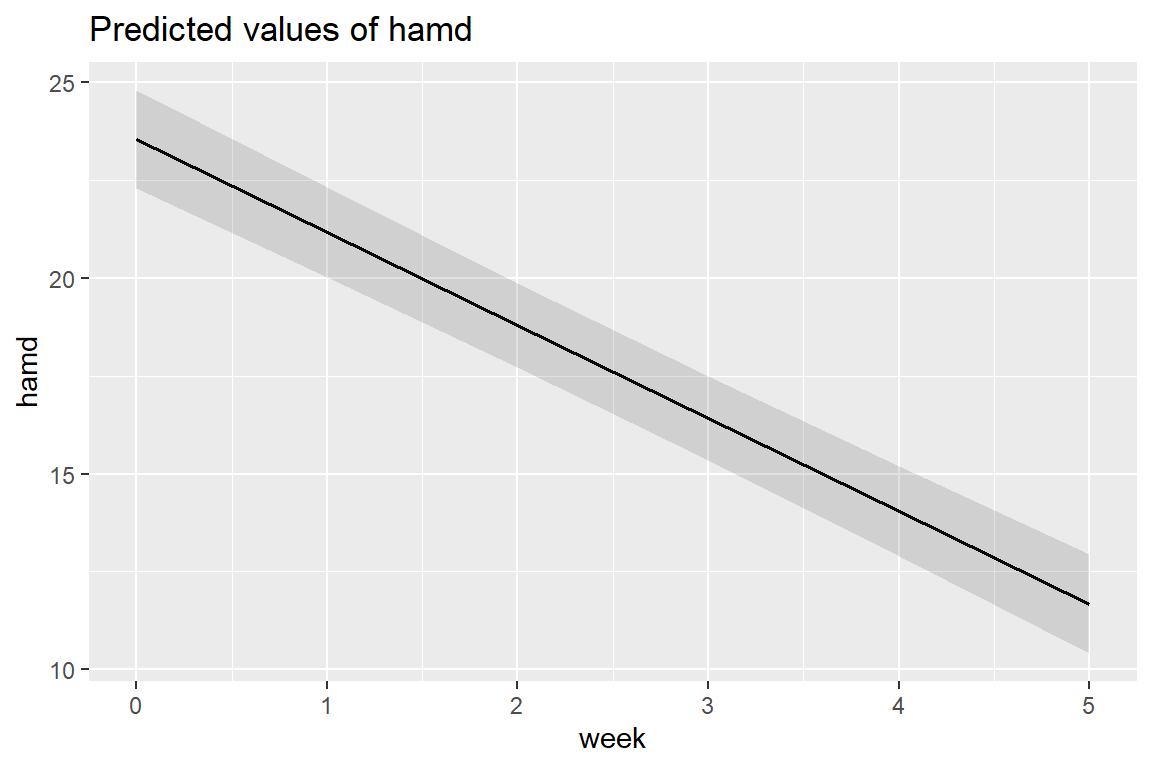
12.4.4 Estimated Marginal Means and Emperical Bayes Plots
With a bit more code we can plot not only the marginal model (fixed effects only), but add the Best Linear Unbiased Predictions (BLUPs) or person-specific specific models (both fixed and random effects).
data_long %>%
dplyr::mutate(pred_fixed = predict(fit_lmer_week_RI_reml,
re.form = NA, # fixed effects only
newdata = .)) %>%
dplyr::mutate(pred_wrand = predict(fit_lmer_week_RI_reml, # fixed and random effects both
newdata = .)) %>%
ggplot(aes(x = week,
y = hamd,
group = id)) +
geom_line(aes(y = pred_wrand,
color = "BLUP",
size = "BLUP",
linetype = "BLUP")) +
geom_line(aes(y = pred_fixed,
color = "Marginal",
size = "Marginal",
linetype = "Marginal")) +
theme_bw() +
scale_color_manual(name = "Type of Prediction",
values = c("BLUP" = "gray50",
"Marginal" = "blue")) +
scale_size_manual(name = "Type of Prediction",
values = c("BLUP" = .5,
"Marginal" = 1.25)) +
scale_linetype_manual(name = "Type of Prediction",
values = c("BLUP" = "longdash",
"Marginal" = "solid")) +
theme(legend.position = c(0, 0),
legend.justification = c(-0.1, -0.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)")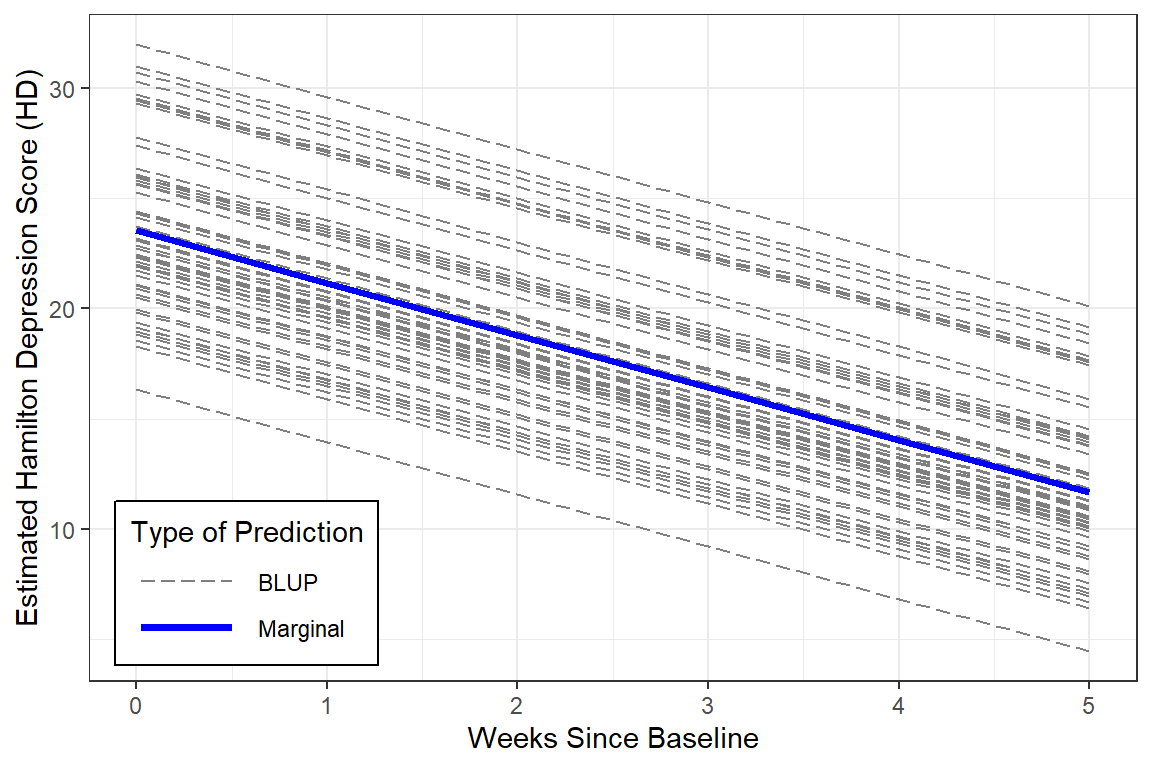
Notice that in this model, all the BLUPs are parallel. That is because we are only letting the intercept vary from person-to-person while keeping the effect of time (slope) constant.
Reproduce Table 4.4 on page 55 (Hedeker and Gibbons 2006)
One way to judge a model is to compare the estimated means to the observed means to see how accuratedly they are represented by the model. This excellent fit of the estimated marginal means to the observed data supports the hypothesis that the change in depression across time is LINEAR.
obs <- data_long %>%
dplyr::group_by(week) %>%
dplyr::summarise(observed = mean(hamd, na.rm = TRUE))
effects::Effect(focal.predictors = "week",
mod = fit_lmer_week_RI_reml,
xlevels = list(week = 0:5)) %>%
data.frame() %>%
dplyr::rename(estimated = fit) %>%
dplyr::left_join(obs, by = "week") %>%
dplyr::select(week, observed, estimated) %>%
dplyr::mutate(diff = observed - estimated) %>%
pander::pander(caption = "Observed and Estimated Means")| week | observed | estimated | diff |
|---|---|---|---|
| 0 | 23 | 24 | -0.11 |
| 1 | 22 | 21 | 0.67 |
| 2 | 18 | 19 | -0.49 |
| 3 | 16 | 16 | -0.01 |
| 4 | 14 | 14 | -0.43 |
| 5 | 12 | 12 | 0.27 |
12.4.5 Intra-individual Correlation (ICC)
performance::icc(fit_lmer_week_RI_reml)# Intraclass Correlation Coefficient
Adjusted ICC: 0.463
Unadjusted ICC: 0.319Interpretation Just less than a third (\(\rho_c = .32\)) in baseline depression is explained by person-to-person differences. Thus, subjects display considerable heterogeneity in depression levels.
This value of .46is an oversimplification of the correlation matrix above and may be thought of as the expected correlation between two randomly drawn weeks for any given person.
performance::r2(fit_lmer_week_RI_reml)# R2 for Mixed Models
Conditional R2: 0.629
Marginal R2: 0.310Interpretation Linear growth accounts for 31% of the variance in Hamilton Depression Scores across the six weeks. Linear growth AND person-to-person differences account for a total 63% of this variance.
This value of 46% is an oversimplification of the correlation matrix above and may be thought of as the expected correlation between two randomly drawn weeks for any given person.
performance::r2(fit_lmer_week_RI_reml)# R2 for Mixed Models
Conditional R2: 0.629
Marginal R2: 0.310Note: The marginal \(R^2\) considers only the variance of the fixed effects, while the conditional \(R^2\) takes both the fixed and random effects into account. The random effect variances are actually the mean random effect variances, thus the \(R^2\) value is also appropriate for mixed models with random slopes or nested random effects (see Johnson 2014).
Interpretation Linear growth accounts for 31% of the variance in Hamilton Depression Scores across the six weeks. Linear growth AND person-to-person differences account for a total 63% of this variance.
Note: The marginal R^2 considers only the variance of the fixed effects, while the conditional R^2 takes both the fixed and random effects into account. The random effect variances are actually the mean random effect variances, thus the R^2 value is also appropriate for mixed models with random slopes or nested random effects (see Johnson 2014).
12.4.6 Compare to the Single-Level Null: No Random Effects
Simple Linear Regression, (Hedeker and Gibbons 2006)
To compare, fit the single level regression model
fit_lm_week_ml <- lm(hamd ~ week,
data = data_long)12.4.6.1 Table of Parameter Estimates
texreg::screenreg(list(fit_lm_week_ml, fit_lmer_week_RI_reml),
custom.model.names = c("Single-Level", "Multilevel"),
single.row = TRUE,
caption = "MLM: Longitudinal Null Models",
caption.above = TRUE,
custom.note = "The singel-level model treats are observations as being independent and unrelated to each other, even if they were made on the same person.")===========================================================
Single-Level Multilevel
———————————————————–
(Intercept) 23.60 (0.55) *** 23.55 (0.64)
week -2.41 (0.18) -2.38 (0.14) ***
———————————————————–
R^2 0.32
Adj. R^2 0.32
Num. obs. 375 375
AIC 2294.73
BIC 2310.43
Log Likelihood -1143.36
Num. groups: id 66
Var: id (Intercept) 16.45
Var: Residual 19.10
===========================================================
The singel-level model treats are observations as being independent and unrelated to each other, even if they were made on the same person.
For the multilevel model, the Wald tests indicated the fixed intercept is significant (no surprised that the depressions scores are not zero at baseline). More of note is the significance of the fixed effect of time. This signifies that depression scores are declining over time. On average, patients are improving (Hamilton Depression Scores get smaller) across time, by an average of 2.4’ish points a week.
For the multilevel model, the Wald tests indicated the fixed intercept is significant (no surprised that the depressions scores are not zero at baseline). More of note is the significance of the fixed effect of time. This signifies that depression scores are declining over time. On average, patients are improving (Hamilton Depression Scores get smaller) across time, by an average of 2.4’ish points a week.
12.4.6.2 Residual Variance
Note, the fixed estimates are very similar for the two models, but the standard errors are different. Additionally, whereas the single-level regression lumps all remaining variance together (\(\sigma^2\)), the multilevel model seperates it into within-subjects (\(\sigma^2_{u0}\) or \(\tau_{00}\)) and between-subjects variance (\(\sigma^2_{e}\) or \(\sigma^2\)).
sigma(fit_lm_week_ml)^2[1] 35.3997lme4::VarCorr(fit_lmer_week_RI_reml) %>% # in longitudinal data, a group of observations = a participant or person
print(comp = c("Variance", "Std.Dev")) Groups Name Variance Std.Dev.
id (Intercept) 16.446 4.0554
Residual 19.099 4.3703 “One statistician’s error term is another’s career!”
(Hedeker and Gibbons 2006), page 56
12.5 MLM: Add Random Slope for Time (i.e. Trend)
12.5.1 Fit the Model
fit_lmer_week_RIAS_reml <- lmerTest::lmer(hamd ~ week + (week|id), # MLM-RIAS
data = data_long,
REML = TRUE)texreg::screenreg(list(fit_lmer_week_RI_reml,
fit_lmer_week_RIAS_reml),
custom.model.names = c("Random Intercepts",
" And Random Slopes"),
single.row = TRUE,
caption = "MLM: Null models fit w/REML",
caption.above = TRUE,
custom.note = "Hedeker table 4.4 on page 55 and table 4.5 on page 58, except using REML here instead of ML")==================================================================
Random Intercepts And Random Slopes
——————————————————————
(Intercept) 23.55 (0.64) *** 23.58 (0.55)
week -2.38 (0.14) -2.38 (0.21) ***
——————————————————————
AIC 2294.73 2231.92
BIC 2310.43 2255.48
Log Likelihood -1143.36 -1109.96
Num. obs. 375 375
Num. groups: id 66 66
Var: id (Intercept) 16.45 12.94
Var: Residual 19.10 12.21
Var: id week 2.13
Cov: id (Intercept) week -1.48
==================================================================
Hedeker table 4.4 on page 55 and table 4.5 on page 58, except using REML here instead of ML
Visually, we can see that the unexplained or residual variance is less (12.21 vs 19.10) for the model that includes person-specific slopes (trajectories over time).
Note: the negative covariance between random intercepts and random slopes (\(\sigma_{u01} = \tau_{01} = -1.48\)):
“This suggests that patients who are initially more depressed (i.e. greater intercepts) improve at a greater rate (i.e. more pronounced negative slopes). An alternative explainatio, though,is that of a floor effect due to the HDRS rating scale. Simply put, patients with less depressed intitial scores have a more limited range of lower scores than those with higher initial scores.”
(Hedeker and Gibbons 2006), page 58
12.5.2 Likelihood Ratio Test
anova(fit_lmer_week_RI_reml, fit_lmer_week_RIAS_reml,
model.names = c("RI", "RIAS"),
refit = FALSE) %>%
pander::pander(caption = "LRT: Assess Significance of Random Slopes")| npar | AIC | BIC | logLik | deviance | Chisq | Df | Pr(>Chisq) | |
|---|---|---|---|---|---|---|---|---|
| RI | 4 | 2295 | 2310 | -1143 | 2287 | NA | NA | NA |
| RIAS | 6 | 2232 | 2255 | -1110 | 2220 | 67 | 2 | 0 |
Including the random slope for time significantly improved the model fit via the formal Likelihood Ratio Test. This rejects the assumption of compound symmetry.
performance::compare_performance(fit_lmer_week_RI_reml,
fit_lmer_week_RIAS_reml,
rank = TRUE)# Comparison of Model Performance Indices
Name | Model | R2 (cond.) | R2 (marg.) | ICC | RMSE | Sigma | AIC weights | AICc weights | BIC weights | Performance-Score
----------------------------------------------------------------------------------------------------------------------------------------------------------
fit_lmer_week_RIAS_reml | lmerModLmerTest | 0.769 | 0.302 | 0.669 | 2.993 | 3.495 | 1.000 | 1.000 | 1.000 | 87.50%
fit_lmer_week_RI_reml | lmerModLmerTest | 0.629 | 0.310 | 0.463 | 4.031 | 4.370 | 3.20e-14 | 3.40e-14 | 1.63e-12 | 12.50%12.5.3 Estimated Marginal Means Plot
sjPlot::plot_model(fit_lmer_week_RIAS_reml,
type = "pred",
terms = c("week"))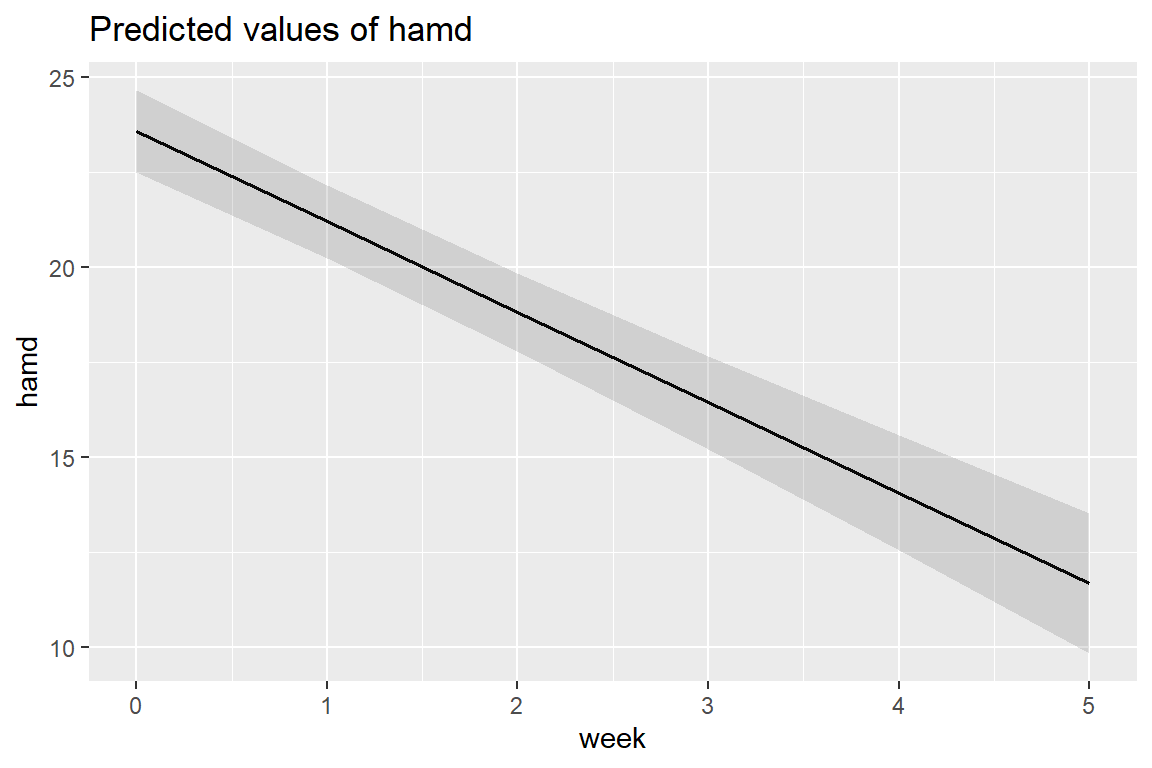
Adding the random slopes didn’t change the estimates for the fixed effects much.
12.5.4 Estimated Marginal Means and Emperical Bayes Plots
data_long %>%
dplyr::mutate(pred_fixed = predict(fit_lmer_week_RIAS_reml,
re.form = NA, # fixed effects only
newdata = .)) %>%
dplyr::mutate(pred_wrand = predict(fit_lmer_week_RIAS_reml, # fixed and random effects together
newdata = .)) %>%
ggplot(aes(x = week,
y = hamd,
group = id)) +
geom_line(aes(y = pred_wrand,
color = "BLUP",
size = "BLUP",
linetype = "BLUP")) +
geom_line(aes(y = pred_fixed,
color = "Marginal",
size = "Marginal",
linetype = "Marginal")) +
theme_bw() +
scale_color_manual(name = "Type of Prediction",
values = c("BLUP" = "gray50",
"Marginal" = "blue")) +
scale_size_manual(name = "Type of Prediction",
values = c("BLUP" = .5,
"Marginal" = 1.25)) +
scale_linetype_manual(name = "Type of Prediction",
values = c("BLUP" = "longdash",
"Marginal" = "solid")) +
theme(legend.position = c(0, 0),
legend.justification = c(-0.1, -0.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score")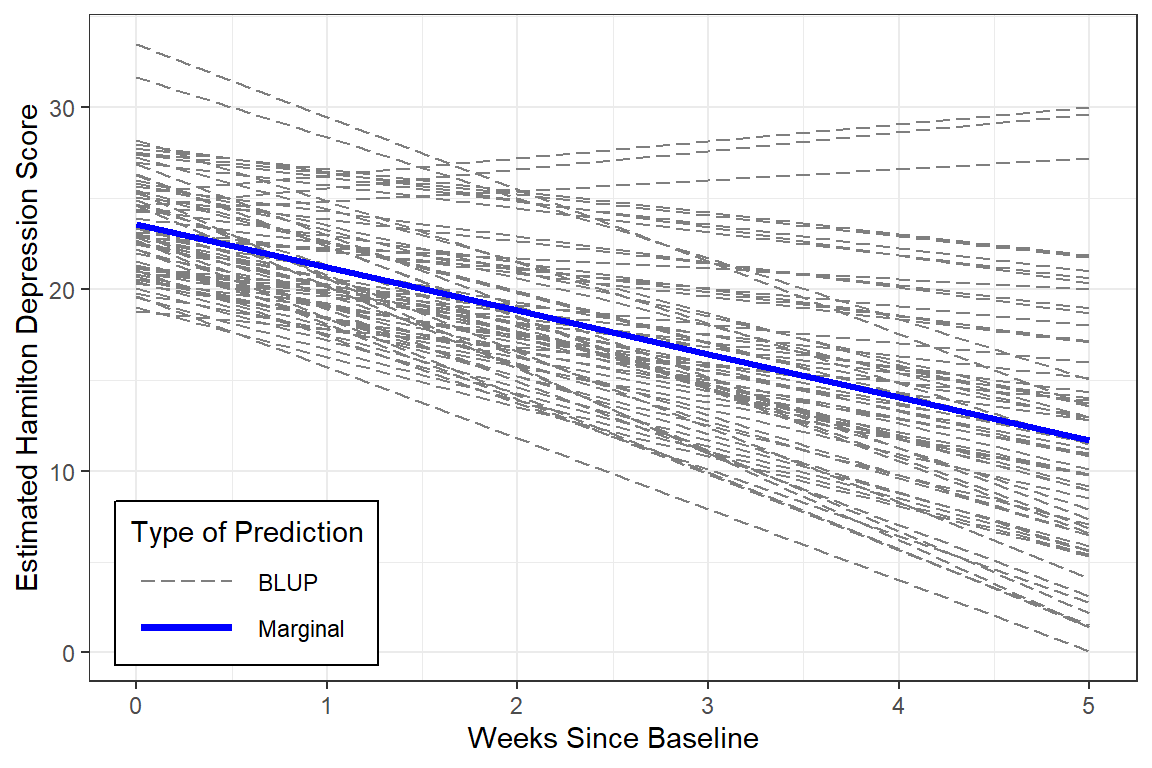
BLUPs are also refered to as Empirical Bayes Estimates and may be extracted from a model fit. In this cases there will be a specific intercept ((Intercept)) and time slope (week) for each individual or person (id).
12.5.4.1 Fixed Effects
Marginal Model = within-subject effects
fixef(fit_lmer_week_RIAS_reml)(Intercept) week
23.577044 -2.377047 12.5.4.2 Random Effects
between-subjects effects
ranef(fit_lmer_week_RIAS_reml)$id %>%
head() # only the first 6 participants (Intercept) week
101 1.0572022 -2.1151378
103 3.6707900 -0.4832479
104 2.6727551 -1.5008819
105 -3.0413391 0.2264496
106 0.3154240 1.0254750
107 -0.6148994 -0.429738512.5.4.3 BLUPs or Empirical Bayes Estimates
fixed effects + random effects
coef(fit_lmer_week_RIAS_reml)$id %>%
head() # only the first 6 participants (Intercept) week
101 24.63425 -4.492185
103 27.24783 -2.860295
104 26.24980 -3.877929
105 20.53571 -2.150598
106 23.89247 -1.351572
107 22.96214 -2.806786We can create a scatterplot of these to see the correlation between them.
coef(fit_lmer_week_RIAS_reml)$id %>%
ggplot(aes(x = week,
y = `(Intercept)`)) +
geom_point() +
geom_hline(yintercept = fixef(fit_lmer_week_RIAS_reml)["(Intercept)"],
linetype = "dashed") +
geom_vline(xintercept = fixef(fit_lmer_week_RIAS_reml)["week"],
linetype = "dashed") +
geom_smooth(method = "lm") +
labs(title = "Hedeker's Figure 4.4 on page 59",
subtitle = "Reisby data: Estimated random effects",
x = "Week Change in Depression",
y = "Baseline Depression Level") +
theme_bw()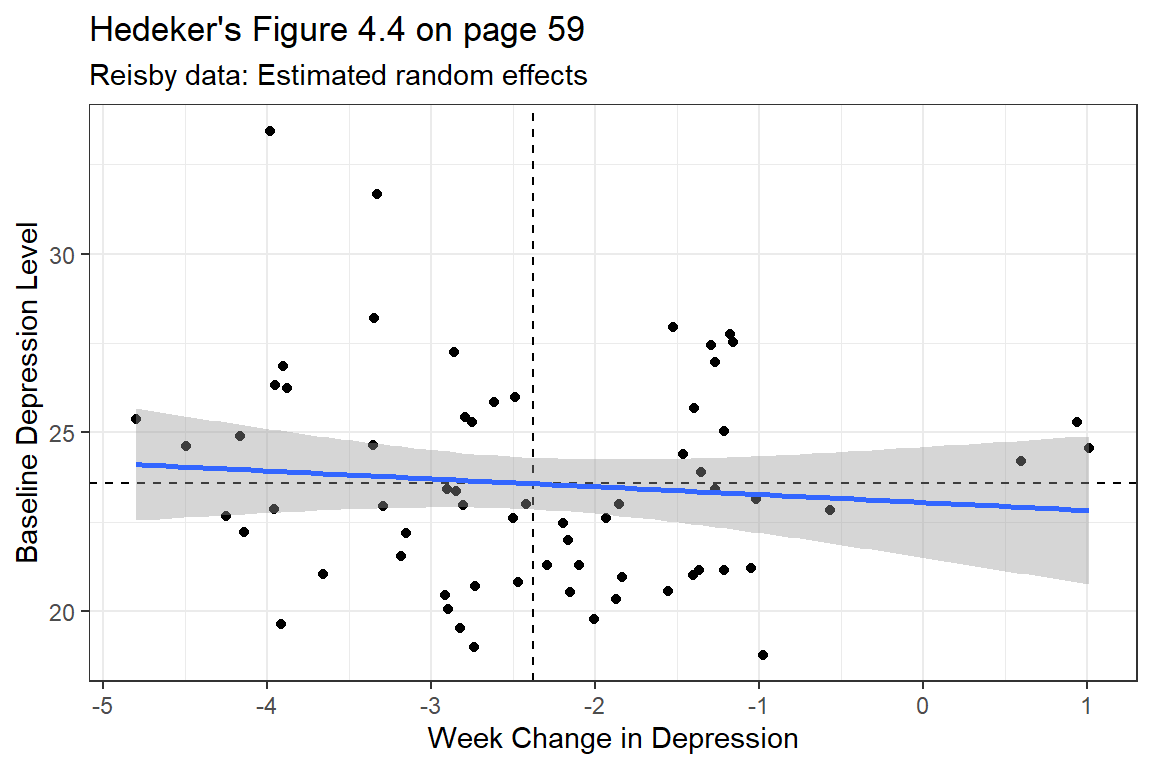
12.6 MLM: Coding of Time
So far we have used the variable week to denote time as weeks since baseline = week \(\in 0, 1, 2, 3, 4, 5\).
But We could CENTER week at the middle of the study (week = 2.5).
12.6.1 Fit the Model
fit_lmer_week_RIAS_reml_wc <- lme4::lmer(hamd ~ I(week-2.5) + (I(week-2.5)|id), # MLM-RIAS
data = data_long,
REML = TRUE)12.6.2 Table of Parameter Estimates
texreg::screenreg(list(fit_lmer_week_RIAS_reml,
fit_lmer_week_RIAS_reml_wc),
custom.model.names = c("Random Intercepts",
" And Random Slopes"),
single.row = TRUE,
caption = "MLM: Null models fit w/REML",
caption.above = TRUE,
custom.note = "Hedeker table table 4.5 on page 58 and table 4.6 on page 61, except using REML here instead of ML")===========================================================================
Random Intercepts And Random Slopes
—————————————————————————
(Intercept) 23.58 (0.55) *** 17.63 (0.56)
week -2.38 (0.21)
week - 2.5 -2.38 (0.21) ***
—————————————————————————
AIC 2231.92 2231.92
BIC 2255.48 2255.48
Log Likelihood -1109.96 -1109.96
Num. obs. 375 375
Num. groups: id 66 66
Var: id (Intercept) 12.94 18.85
Var: id week 2.13
Cov: id (Intercept) week -1.48
Var: Residual 12.21 12.21
Var: id I(week - 2.5) 2.13
Cov: id (Intercept) I(week - 2.5) 3.84
===========================================================================
Hedeker table table 4.5 on page 58 and table 4.6 on page 61, except using REML here instead of ML
Unchanged
model fit: AIC, BIC, -2LL, residual variance
fixed effect of week
variance for random intercepts
Changed
fixed intercept
variance for random slopes
covariance between random intercepts and random slopes
- model fit: AIC, BIC, -2LL, residual variance
- fixed effect of week
- variance for random intercepts
- model fit: AIC, BIC, -2LL, residual variance
Changed
- fixed intercept
- variance for random slopes
- covariance between random intercepts and random slopes
- fixed intercept
12.6.3 Estimated Marginal Means and Emperical Bayes Plots
data_long %>%
dplyr::mutate(pred_fixed = predict(fit_lmer_week_RIAS_reml_wc,
re.form = NA,
newdata = .)) %>% # fixed effects only
dplyr::mutate(pred_wrand = predict(fit_lmer_week_RIAS_reml_wc,
newdata = .)) %>% # fixed and random effects together
ggplot(aes(x = week,
y = hamd,
group = id)) +
geom_line(aes(y = pred_wrand,
color = "BLUP",
size = "BLUP",
linetype = "BLUP")) +
geom_line(aes(y = pred_fixed,
color = "Marginal",
size = "Marginal",
linetype = "Marginal")) +
theme_bw() +
scale_color_manual(name = "Type of Prediction",
values = c("BLUP" = "gray50",
"Marginal" = "blue")) +
scale_size_manual(name = "Type of Prediction",
values = c("BLUP" = .5,
"Marginal" = 1.25)) +
scale_linetype_manual(name = "Type of Prediction",
values = c("BLUP" = "longdash",
"Marginal" = "solid")) +
theme(legend.position = c(0, 0),
legend.justification = c(-0.1, -0.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Score (HD)")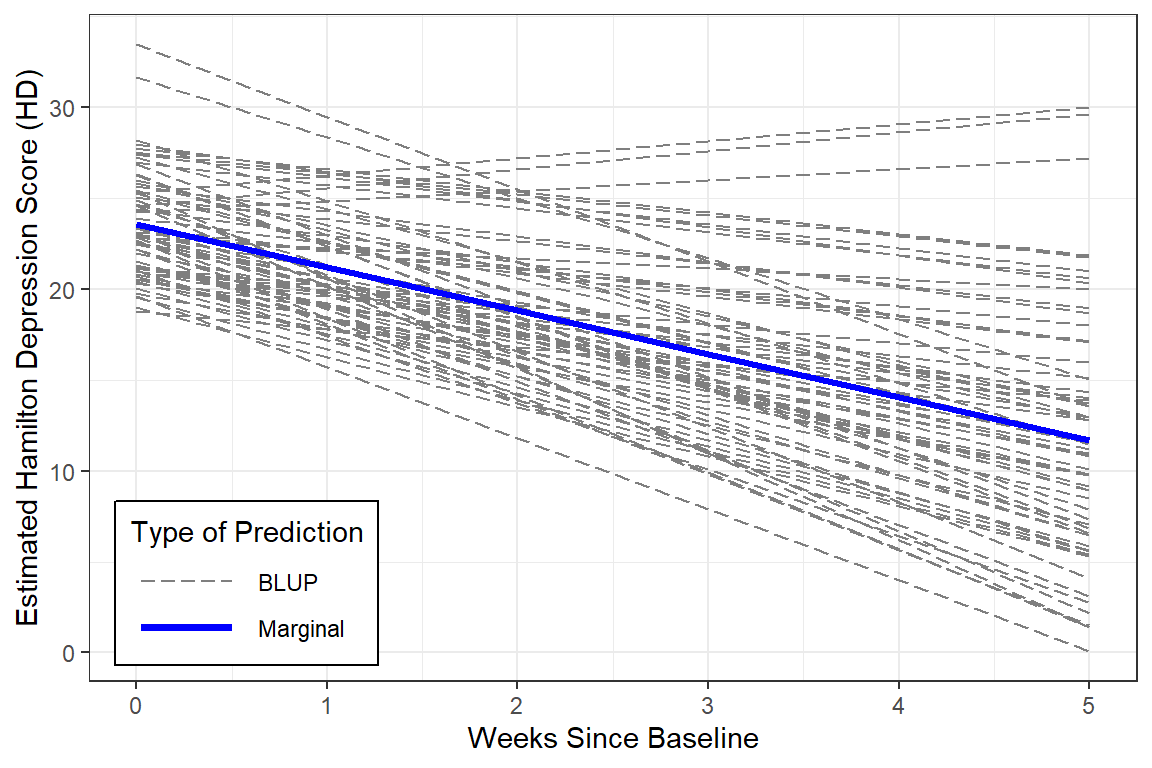
Again, centering time doesn’t change the interpretation at all, since there are no interactions.
12.7 MLM: Effect of DIagnosis on Time Trends (Fixed Interaction)
The researcher specifically wants to know if the trajectory over time differs for the two types of depression. This translates into a fixed effects interaction between time and group.
Start by comapring random intercepts only (RI) to a random intercetps and slopes (RIAS) model.
12.7.1 Fit the Models
fit_lmer_week_RIAS_ml <- lmerTest::lmer(hamd ~ week + (week|id),
data = data_long,
REML = FALSE)
fit_lmer_wkdx_RIAS_ml <- lmerTest::lmer(hamd ~ week*endog + (week|id),
data = data_long,
REML = FALSE)12.7.2 Estimated Marginal Meanse Plot
interactions::interact_plot(fit_lmer_wkdx_RIAS_ml,
pred = week,
modx = endog,
legend.main = "Type of Depression",
interval = TRUE,
main.title = "Hedeker's Table 4.7 on page 64") +
theme_bw() +
labs(x = "Weeks Since Baseline",
y = "Estimated Marginal Mean\nHamilton Depression Scores (HD)") +
theme(legend.background = element_rect(color = "black"),
legend.position = c(0, 0),
legend.justification = c(-0.1, -0.1),
legend.key.width = unit(1.75, "cm"))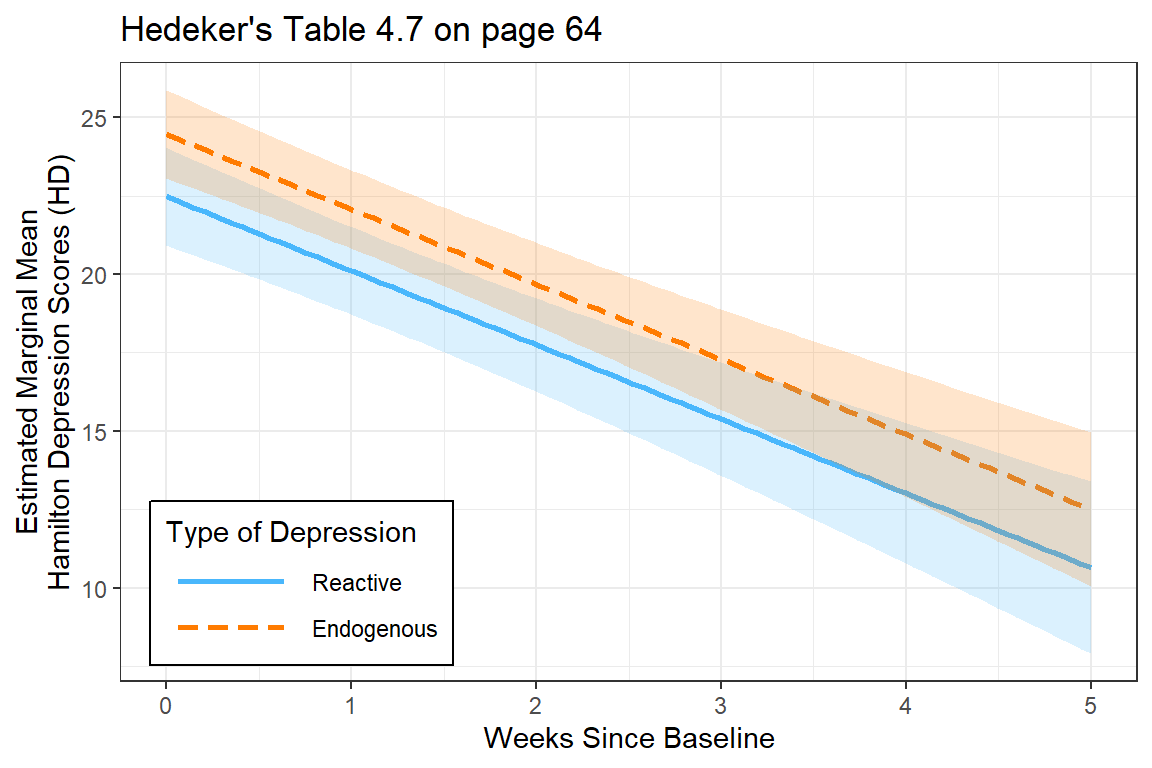
12.7.3 Likelihood Ratio Test
anova(fit_lmer_week_RIAS_ml,
fit_lmer_wkdx_RIAS_ml,
model.names = c("Just Time",
"Time X Dx")) %>%
pander::pander(caption = "LRT: Assess Significance of Diagnosis Moderation of Trend")| npar | AIC | BIC | logLik | deviance | Chisq | Df | Pr(>Chisq) | |
|---|---|---|---|---|---|---|---|---|
| Just Time | 6 | 2231 | 2255 | -1110 | 2219 | NA | NA | NA |
| Time X Dx | 8 | 2231 | 2262 | -1107 | 2215 | 4.1 | 2 | 0.13 |
performance::compare_performance(fit_lmer_week_RIAS_ml,
fit_lmer_wkdx_RIAS_ml,
rank = TRUE)# Comparison of Model Performance Indices
Name | Model | R2 (cond.) | R2 (marg.) | ICC | RMSE | Sigma | AIC weights | AICc weights | BIC weights | Performance-Score
--------------------------------------------------------------------------------------------------------------------------------------------------------
fit_lmer_week_RIAS_ml | lmerModLmerTest | 0.767 | 0.305 | 0.665 | 2.999 | 3.495 | 0.486 | 0.507 | 0.980 | 62.50%
fit_lmer_wkdx_RIAS_ml | lmerModLmerTest | 0.768 | 0.324 | 0.656 | 3.005 | 3.495 | 0.514 | 0.493 | 0.020 | 37.50%The more complicated model (including the moderating effect of diagnosis) is NOT supported.
The more complicated model (including the moderating effect of diagnosis) is NOT supported.
12.8 MLM: Quadratic Trend
12.8.1 Fit the Model
fit_lmer_quad_RIAS_ml <- lme4::lmer(hamd ~ week + I(week^2) + (week+ I(week^2)|id),
data = data_long,
REML = FALSE,
control = lmerControl(optimizer = "optimx", # get it to converge
calc.derivs = FALSE,
optCtrl = list(method = "nlminb",
starttests = FALSE,
kkt = FALSE))) 12.8.2 Table of Parameter Estimates
texreg::screenreg(list(fit_lmer_week_RIAS_ml,
fit_lmer_quad_RIAS_ml),
custom.model.names = c("Linear Trend",
"QUadratic Trend"),
single.row = TRUE,
caption = "MLM: RIAS models fit w/ML",
caption.above = TRUE,
custom.note = "Hedeker table 4.5 on page 58 and table 5.1 on page 84")=======================================================================
Linear Trend QUadratic Trend
———————————————————————–
(Intercept) 23.58 (0.55) *** 23.76 (0.55)
week -2.38 (0.21) -2.63 (0.48) ***
week^2 0.05 (0.09)
———————————————————————–
AIC 2231.04 2227.65
BIC 2254.60 2266.92
Log Likelihood -1109.52 -1103.82
Num. obs. 375 375
Num. groups: id 66 66
Var: id (Intercept) 12.63 10.44
Var: id week 2.08 6.64
Cov: id (Intercept) week -1.42 -0.92
Var: Residual 12.22 10.52
Var: id I(week^2) 0.19
Cov: id (Intercept) I(week^2) -0.11
Cov: id week I(week^2) -0.94
=======================================================================
Hedeker table 4.5 on page 58 and table 5.1 on page 84
12.8.3 Likelihood Ratio Test
anova(fit_lmer_week_RIAS_ml, fit_lmer_quad_RIAS_ml)Data: data_long
Models:
fit_lmer_week_RIAS_ml: hamd ~ week + (week | id)
fit_lmer_quad_RIAS_ml: hamd ~ week + I(week^2) + (week + I(week^2) | id)
npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
fit_lmer_week_RIAS_ml 6 2231.0 2254.6 -1109.5 2219.0
fit_lmer_quad_RIAS_ml 10 2227.7 2266.9 -1103.8 2207.7 11.39 4 0.02252 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1performance::compare_performance(fit_lmer_week_RIAS_ml,
fit_lmer_quad_RIAS_ml,
rank = TRUE)# Comparison of Model Performance Indices
Name | Model | R2 (cond.) | R2 (marg.) | ICC | RMSE | Sigma | AIC weights | AICc weights | BIC weights | Performance-Score
--------------------------------------------------------------------------------------------------------------------------------------------------------
fit_lmer_quad_RIAS_ml | lmerMod | 0.799 | 0.306 | 0.710 | 2.656 | 3.243 | 0.845 | 0.819 | 0.002 | 87.50%
fit_lmer_week_RIAS_ml | lmerModLmerTest | 0.767 | 0.305 | 0.665 | 2.999 | 3.495 | 0.155 | 0.181 | 0.998 | 12.50%Even though the Wald test did not find the quadratic fixed time trend to be significant at the population level (marginal), the LRT and Bayes Factor both find that including the quadratic terms improves the model’s fit.
12.8.4 Estimated Marginal Means Plot
fixef(fit_lmer_quad_RIAS_ml)(Intercept) week I(week^2)
23.7602494 -2.6325756 0.0514812 sjPlot::plot_model(fit_lmer_quad_RIAS_ml,
type = "pred",
terms = "week")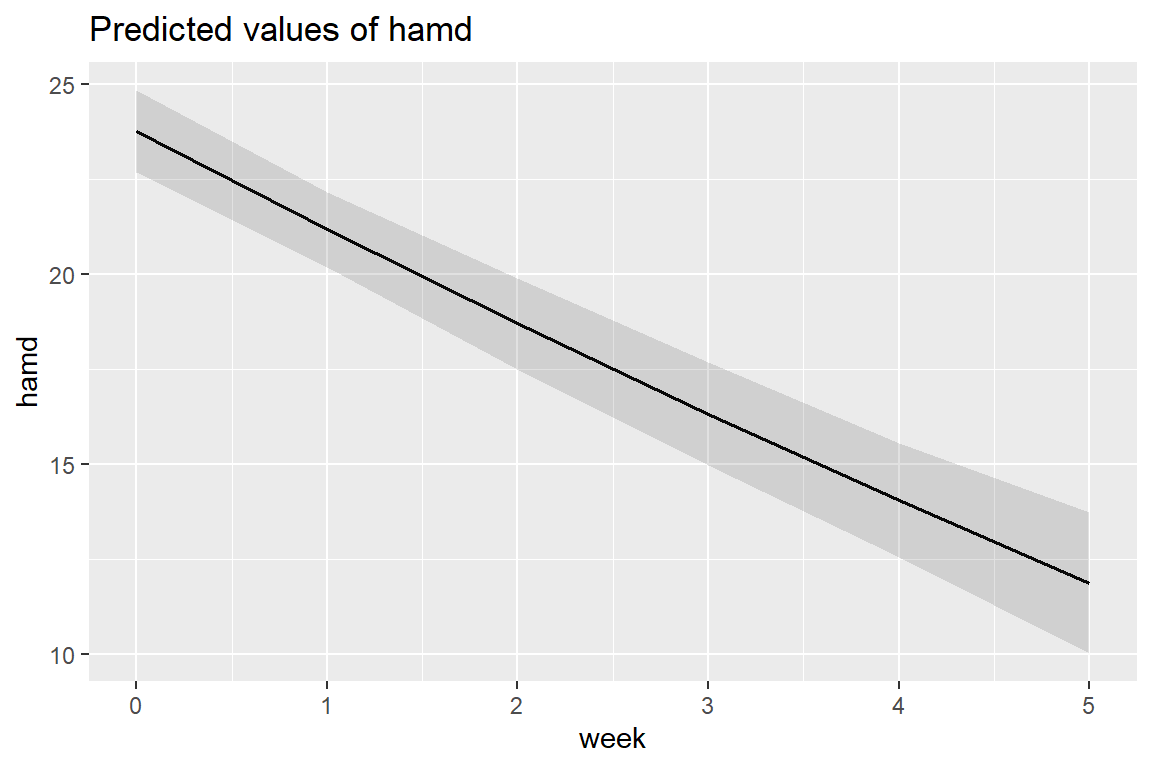
At the population level, the curviture is very slight.
12.8.5 BLUPs or Emperical Bayes Estimates
coef(fit_lmer_quad_RIAS_ml)$id (Intercept) week I(week^2)
101 25.16570 -5.28322240 0.150800674
103 27.50748 -3.43493956 0.119896419
104 25.99803 -3.09403830 -0.176872891
105 21.01142 -2.95259656 0.164659508
106 23.64345 -0.74433445 -0.141870771
107 22.70271 -1.98455785 -0.179103989
108 22.40954 -4.72427651 0.316018682
113 22.70933 -0.40479722 -0.023813901
114 21.71498 -4.51593943 0.305503156
115 21.54596 -2.55733919 0.139466228
117 20.68537 -3.87699771 0.196724980
118 25.37073 -2.57669407 -0.047611415
120 21.54364 -2.02854721 0.175309140
121 22.58017 -1.75375731 -0.038804946
123 19.25420 -2.87311398 0.017541231
302 21.58631 -3.89088841 0.294414722
303 22.46072 -3.40753058 0.044346959
304 24.67540 -0.37917299 -0.166164154
305 21.27400 -3.68029144 -0.010285277
308 23.09149 -2.47011411 0.005956521
309 22.90664 -1.55837647 -0.062499088
310 23.05814 -5.82990155 0.392499635
311 21.32623 -1.62724378 0.056406903
312 20.97723 -0.80434902 -0.285843319
313 21.61301 -4.45108620 0.355814498
315 25.23223 -4.58345009 0.080217902
316 27.75572 -1.45600475 0.069630733
318 20.56468 -0.29405182 -0.235309874
319 22.38191 -4.51711991 0.466348405
322 24.93395 1.26791161 -0.042516486
327 19.82905 -3.17595117 0.466782622
328 23.74555 1.29273058 -0.129018797
331 21.92609 -1.83148914 -0.074416221
333 23.11844 -0.64672472 -0.127987413
334 27.19417 -6.33068103 0.497614736
335 22.72435 -2.57422424 0.010287299
337 25.62004 -2.06606297 -0.118350517
338 22.89845 -0.54279462 -0.095537656
339 24.27807 -4.99290658 0.444972811
344 22.43030 -4.34890283 0.557804359
345 27.22532 -1.03851709 -0.044991723
346 24.66105 -2.09386084 0.138720903
347 20.11423 -3.85553234 0.239870351
348 23.42449 -4.05934676 0.152402219
349 20.49506 -3.30475825 0.269601249
350 23.29832 -3.86555727 0.351772013
351 27.85603 -2.54763708 -0.174396178
352 21.86125 -2.47215139 0.305548813
353 25.44900 -1.25790363 -0.261970988
354 26.94737 0.07803738 -0.289824519
355 24.47061 -2.72958140 -0.141017454
357 25.37351 -0.82942969 -0.114172086
360 24.04647 1.73527936 -0.131113157
361 25.48492 -7.37199852 0.953498020
501 27.83195 -1.46848824 -0.003539941
502 22.99362 -4.51402723 0.038610802
504 20.80201 -2.67922623 0.167674789
505 20.96546 -6.31343151 0.490343064
507 26.25982 0.08284389 -0.277546320
603 25.55712 -3.23921928 0.099756125
604 26.04326 -6.06913362 0.284971682
606 24.47426 -3.73162024 -0.178376508
607 31.08955 1.15553930 -1.091093331
608 23.46558 -4.87963779 0.180136913
609 25.91657 -2.23143989 -0.347099437
610 30.62475 -0.54536532 -0.593017239For Illustration, two cases have been hand selected: id = 115 and 610.
fun_115 <- function(week){
coef(fit_lmer_quad_RIAS_ml)$id["115", "(Intercept)"] +
coef(fit_lmer_quad_RIAS_ml)$id["115", "week"] * week +
coef(fit_lmer_quad_RIAS_ml)$id["115", "I(week^2)"] * week^2
}
fun_610 <- function(week){
coef(fit_lmer_quad_RIAS_ml)$id["610", "(Intercept)"] +
coef(fit_lmer_quad_RIAS_ml)$id["610", "week"] * week +
coef(fit_lmer_quad_RIAS_ml)$id["610", "I(week^2)"] * week^2
}data_long %>%
dplyr::mutate(pred_fixed = predict(fit_lmer_quad_RIAS_ml,
re.form = NA,
newdata = .)) %>% # fixed effects only
dplyr::mutate(pred_wrand = predict(fit_lmer_quad_RIAS_ml,
newdata = .)) %>% # fixed and random effects together
ggplot(aes(x = week,
y = hamd,
group = id)) +
stat_function(fun = fun_115) + # add cure for ID = 115
stat_function(fun = fun_610) + # add cure for ID = 610
geom_line(aes(y = pred_fixed),
color = "blue",
size = 1.25) +
theme_bw() +
theme(legend.position = c(0, 0),
legend.justification = c(-0.1, -0.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Scores (HD)",
title = "Similar to Hedeker's Figure 5.3 on page 84",
subtitle = "Marginal Mean show in thicker blue\nBLUPs for two of the participant in thinner black")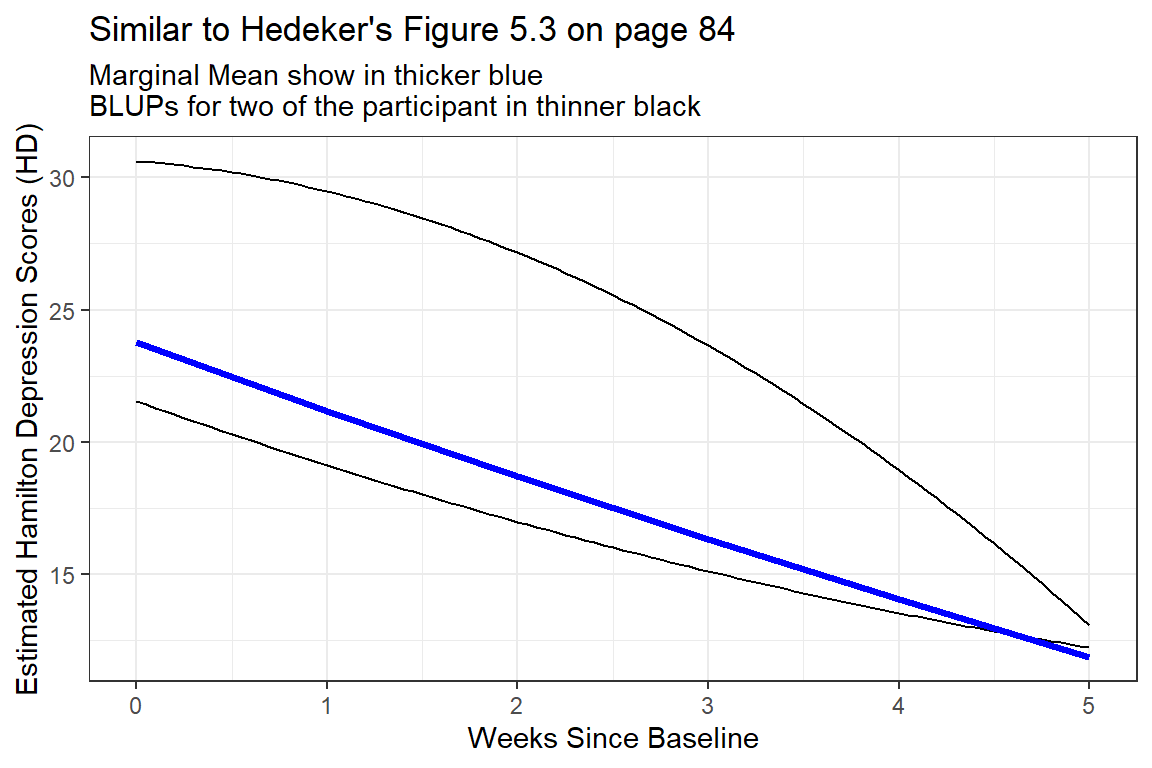
Figure 12.1: Two Example BLUPS for two different participants
These two individuals have quite different curvatures and illustrated how this type of curvatures in person-specific trajectories may end up cancelling each other out to arrive at a fairly linear marginal model.
12.8.6 Estimated Marginal Means and Emperical Bayes Plots
Note: although the BLUPs are shown for all participants, the predictions are just connects and are therefore slightly jagged and now smoother like the lines on the plot above.
data_long %>%
dplyr::mutate(pred_fixed = predict(fit_lmer_quad_RIAS_ml,
re.form = NA,
newdata = .)) %>% # fixed effects only
dplyr::mutate(pred_wrand = predict(fit_lmer_quad_RIAS_ml,
newdata = .)) %>% # fixed and random effects together
ggplot(aes(x = week,
y = hamd,
group = id)) +
geom_line(aes(y = pred_wrand,
color = "BLUP",
size = "BLUP",
linetype = "BLUP")) +
geom_line(aes(y = pred_fixed,
color = "Marginal",
size = "Marginal",
linetype = "Marginal")) +
theme_bw() +
scale_color_manual(name = "Type of Prediction",
values = c("BLUP" = "gray50",
"Marginal" = "blue")) +
scale_size_manual(name = "Type of Prediction",
values = c("BLUP" = .5,
"Marginal" = 1.25)) +
scale_linetype_manual(name = "Type of Prediction",
values = c("BLUP" = "longdash",
"Marginal" = "solid")) +
theme(legend.position = c(0, 0),
legend.justification = c(-0.1, -0.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(1.5, "cm")) +
labs(x = "Weeks Since Baseline",
y = "Estimated Hamilton Depression Scores",
title = "Hedeker's Figure 5.4 on page 85")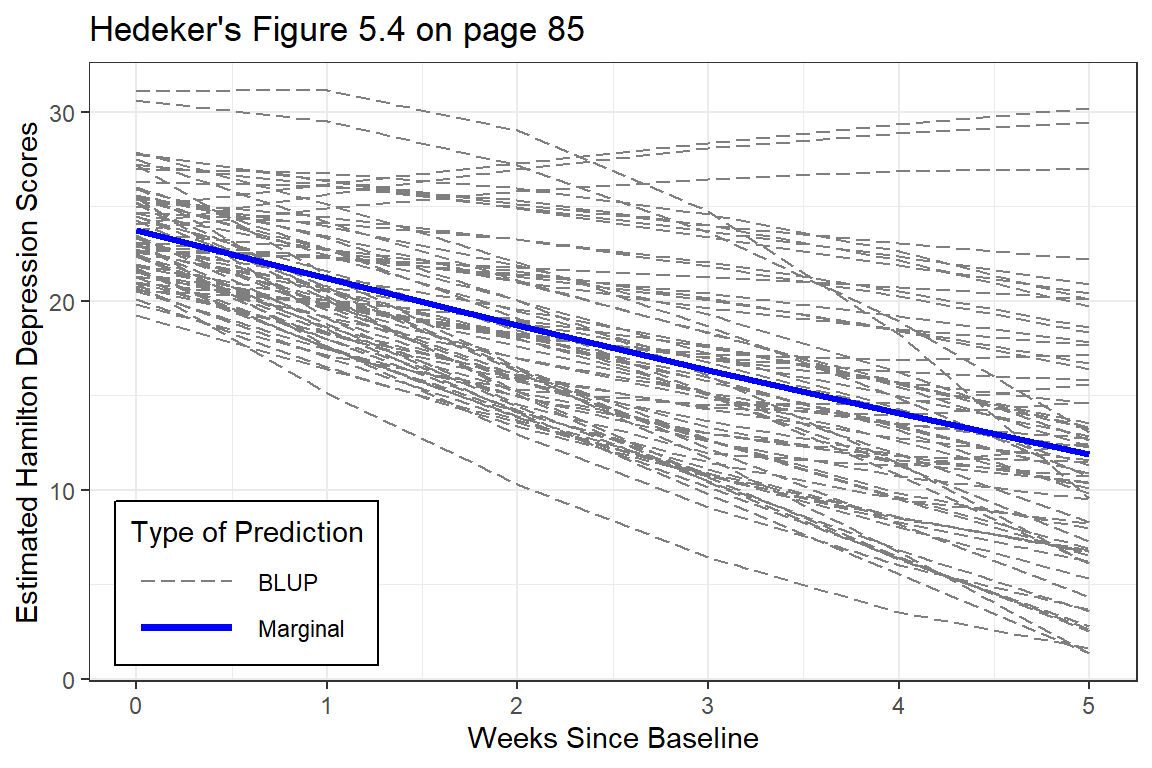
Figure 12.2: EStimated curvilinear trends
At the person-level, the curvature is very diverse (heterogeneous). Some individuals have accelerating downward tend while other have accelerating upward trends.
The improvement that the curvi-linear model provides in describing change across time is perhaps modest.